
티스토리 뷰
스스로 번역한 내용이라 오역 있을 수 있음
Computer Vision
컴퓨터 비전은 visual data[시각 데이터]에 대한 연구이다. Visual data의 양은 계속해서 증가하고 있는데, 2017년에 모든 인터넷의 80%에 해당하는 자료가 비디오가 될 것이다는 CISCO의 연구도 있다.

Visual data는 문제가 하나 있는데, 바로 이해하기가 너무 어렵다는 것. Visual data를 인터넷의 암흑 물질(Dark matter)이라고 비유하기도 하는데. 암흑 물질은 우주의 질량의 많은 부분을 차지하고 있지만 천체에 대한 중력의 존재로 암흑 물질이 존재하는 것을 알뿐 직접적으로 관찰할 수는 없다.
※ 암흑물질 (Dark Matter) : 우주의 총 에너지의 대략 23%를 차지하며, 나머지는 가시광선으로 관측할 수 있는 물질과 암흑 에너지(Dark energy)로 이루어진다는 것이 현재의 이론. 물질만을 고려하면 암흑 물질은 우주 전체 물질의 84.5%를 차지하며, 암흑에너지와 암흑물질은 전체 구성 중 약 96%를 차지한다.
이렇듯 인터넷의 visual data 역시 마찬가지인데, 인터넷을 둘러싼 대부분의 bits로 구성되어 있지만 알고리즘이 실제로 들어가서 웹상의 모든 visual data를 정확히 무엇이 구성하는지 이해하고 보는 것은 매우 어렵기 때문이다.
History of Vision
Biological vision
Vision에 대한 역사는 많은 시간을 거슬러 가야 하는데 (정확히는 5억 4300만 년 전) 그 당시 지구는 대부분 물로 덮여 있었고 아주 적은 생명만이 바다를 떠다녔을 뿐이었다. 그러다 놀라운 일이 5억 4000만 년 전에 발생하게 되는데. 화석을 연구하던 동물연구 학자가 매우 짧은 기간 동안(1000만 년) 동물의 종류가 폭발적으로 증가했다는 것을 찾아낸다.
겨우 몇 종에서 수십만 종으로 넘어가는 과정은 분명 이상한 일일 것이다. 과연 무엇이 이 현상을 만들었을까? 많은 이론이 있기는 하지만 오랜 기간 동안 미스터리로 남았었다. 진화 생물학자들은 이것을 "진화의 빅뱅"이라고 부르는데, 호주 동물학자인 Andrew Parker가 화석 연구 중 바로 약 5억 4000만 년 전에 첫 번째 동물의 눈과 시력이 발달함에 따라 이 폭발적인 진화 단계가 시작되었다는 가장 설득력 있는 이론을 제시하게 된다.
일단 볼 수 있게 되면 삶은 훨씬 더 능동적이게 된다. 일부 포식자는 사냥을 하고 피식자는 포식자로부터 도망쳐야 하므로 시력의 진화 또는 발명은 진화론 적 군비 경쟁을 시작하게 하였으며 종족으로 살아남기 위해서는 동물이 빠르게 진화해야만 했다. 그리고 이것이 동물의 vision의 시작이다.
5억 4000만 년이 지난 후에 시각은 거의 모든 동물, 특히 영리한 동물의 가장 큰 감각 기관으로 발전했는데.
인간은 시각 처리에 관련된 피질(cortex)의 거의 50%에 해당하는 뉴런을 가지고 있다.
우리가 생존하고, 일하고, 움직이고, 조작하고, 의사소통하고 그 외 많은 것들을 가능하게 하는 가장 큰 감각 시스템으로 시각은 동물 (특히 영리한 동물)에게는 정말로 중요하다.
Human vision
기계적인 시각 혹은 카메라를 만드는 인간의 역사는 어떨까? 초기 카메라 중 하나는 1600년대 르네상스 시대의 카메라 'Obscura'에서 나온 것이다.

이 카메라는 핀홀(Pinhole) 카메라 이론에 기반을 둔 카메라이며 동물들이 빛을 모으기 위해 발달한 초기의 눈과 매우 유사하다. 생물 학자들은 시력의 메커니즘을 연구하기 시작했는데, computer vision뿐만 아니라 동물의 시각과 인간 시각의 가장 영향력 있는 작업 중 하나는 전기생리학(electrophysiology)을 사용하는 1950~60년대 Hubel과 Wiesel이 수행한 작업이다. 그들이 물었던 질문은 영장류와 포유류에서와 같은 시각적 메커니즘은 무엇인가?였다.
그래서 그들은 시각적 처리 관점에서 인간의 뇌와 어느 정도 유사한 고양이 뇌를 연구하기로 결심했으며, 그들이 한 일은 주요 시각 피질 영역이 있는 고양이 두뇌의 뒷부분에 전극을 찔러 넣고. 그 다음 고양이 뇌의 주요 시각 피질의 뒷부분의 뉴런을 흥분시키는 자극을 보는 것이었다.

그렇게 알게 된 사실은 고양이 두뇌의 주요 시각 피질 부분에 많은 종류의 세포가 있다는 것이었다. 그러나 가장 중요한 세포 중 하나는 특정 방향으로 움직일 때 지향성(oriented) edge에 반응하는 단순 세포였다. 물론 더 복잡한 세포도 있지만, 그들이 발견한 것은 시각적인 처리가 시각적 세계의 단순한 구조, 지향적인 윤곽기반에서부터 시작되고 정보가 시각적 처리 경로를 따라 이동함에 따라 뇌가 복잡한 시각 세계를 인식할 때까지 시각 정보의 복잡성을 구축하게 된다.
Computer vision
따라서 컴퓨터 비전의 역사 역시 1960 년대 초반부터 시작된다. Block world는 Larry Roberts가 출판 한 작품으로, 시각적 세계가 단순한 기하학적 모양으로 단순화되고 목표가 인식 할 수 있는 컴퓨터 비전의 첫 번째 PHD 학위 논문 중 하나로 널리 알려져 있다.

1966 년에 Summer Vision Project라는 유명한 MIT 여름 프로젝트가 있었는데. 이 프로젝트의 목표는 visual system의 중요한 부분을 구성하는 데 바로 여름 노동자들을 효율적으로 사용하려는 시도였다. 50여 년이 지난 지금도 컴퓨터 비전 분야는 한 여름 프로젝트에서 전 세계 수 천명의 연구자들로 피어나고 있으며, 여전히 vision의 가장 근본적인 문제 중 일부를 다루고 있다. 아직 vision을 해결하지 못했지만 인공 지능 분야에서 가장 중요하고 빠르게 성장하는 분야 중 하나가 되었다.
또 한 명의 경의를 표해야 할 사람은 'David Marr'이다. MIT 과학자로 1970년대 후반에 그의 vision에 대한 생각과 우리가 computer vision에 대해 어떻게 접근해야 하는지 그리고 컴퓨터로 시각적 세계(visual world)를 인식할 수 있게 하는 알고리즘을 개발하는 것에 대한 영향력 있는 책을 저술했다. 그 책의 내용은 이미지를 취하고 시각적 세계의 마지막인 3차원 표현에 도달하기 위해 여러 과정을 거쳐야 한다는 것이다.

첫 번째 과정은 '원시 스케치 (primal sketch)'라고 부른다. 대부분 가장자리, 바, 끝, 가상 선, 커브, 경계가 표현되는 곳이며 신경과학자(neuroscientist)들이 보았던 것에서 영감을 받았다. Hubel과 Wiesel은 시각적 처리의 초기 단계가 모서리(edge)와 같은 간단한 구조와 관련이 있다고 말했다.
다음 단계는 2-and-half-D sketch라고 부른다. visual scene의 surfaces, depth information, layers 또는 시각 화면의 불연속 부분을 함께 조각하기 시작한 다음 결국 모든 것을 모아서 surface 및 volumetric primitives 등을 통해 계층적으로(hierarchically organized) 구성된 3차원 모델을 갖게 되는데 이것은 vision이 무엇인지와 그러한 사고방식에 대한 매우 이상적인 사고 과정이었다. 실제로 수십 년 동안 computer vision을 지배해 왔으며 학생들이 시각 영역(field of visual)에 들어가서 시각적 정보를 분석하는 방법을 생각하는 데 매우 직관적인 방법이기도 하다.
1970년대에 또 하나의 매우 중요한 세미나 그룹이 생겨났다. 사람들이 "단순한 블록 세계를 넘어서 어떻게 현실 세계의 대상을 인식하고 표현할 수 있을까?"하는 질문을 하기 시작했다. 그 당시를 생각해보면, 사용 가능한 데이터가 거의 없다시피 했으며 컴퓨터는 느리고 PC도 주변에 있지 않았지만 컴퓨터 과학자들은 우리가 어떻게 물체를 인식하고 표현할 수 있는지 생각하기 시작했다. 그래서 스탠포드와 SRI(Standford Research Insititue) 두 그룹에서 과학자들이 유사한 아이디어를 제안했는데 하나는 일반화된 실린더(generalized cylinder) 다른 하나는 그림구조(pictorial structure)라고 불렀다.

기본 개념은 모든 객체가 단순한 기하학적 기본 요소로 구성된다는 것이다. 예를 들어 사람은 "일반화된 실린더" 모양으로 함께 결합될 수 있거나 혹은 사람은 그들의 탄성 거리(elastic distance)에 있는 핵심 부분(critical part)에 의해 결합될 수 있다는 것. 따라서 어느 표현이라도 객체의 복잡한 구조를 더 단순한 형태의 집합과 기하학적 구성으로 축소하는 방법이다.
이런 작업들은 몇년간 꽤나 영향력이 있었으며 1980년대에는 David Lowe가 단순한 세계 구조에서 시각적 세계를 재구성하거나 인식하는 방법을 생각하기도 했다.
그 당시 computer vision의 과제가 무엇인지 생각하려는 많은 노력들이 있었는데 1960 ~ 80년대에는 물체 인식에 대한 문제를 풀기가 너무 어려웠다. 위의 내용들은 분명 야심차고 대담한 시도이지만 장난 수준에 불과하다. 현실세계에서 작동할 수 있는 무언가를 제공한다는 측면에서는 많은 진전이 없었기 때문인데. 그래서 사람들은 vision을 해결하는 데 있어 무엇이 문제인지 생각하게 되는데 한 가지 중요한 내용은 다음과 같다.
객체 인식이 너무 어려울 경우, 객체 분할을 먼저 수행해야 한다. 즉, 이미지를 가져와서 픽셀을 의미 있는 영역으로 그룹화해야 하는 것.
우리가 그룹으로 묶인 픽셀을 사람이라고 부를 수 있는지 알 수 없지만 그 배경을 보고 사람에게 속한 모든 픽셀들을 추출할 수는 있는데. 이것을 영상분할(image segmentation)이라고 한다.
Image segmentation : Computer vision에서 분할은 디지털 영상을 여러개의 픽셀 집합으로 나누는 과정을 말하는데 그 의미는 영상의 표현을 좀 더 의미있고 해석하기 쉬운 것으로 단순화하거나 변환하는 것이다.
영상분할 문제에 대한 그래픽 이론 알고리즘을 사용한 아주 초기의 작품이 있는데. Computer vision의 얼굴 인식에 대한 문제이다. 1999년에서 2000년 사이에 machine learning이 추진력을 얻기 시작하는데. 이는 vector machine, boosting과 neural network(신경망)의 첫 번째 물결을 포함한 그래픽 모델이다. 많은 기여를 한 작업은 AdaBoost 알고리즘을 사용한 Paul Viola와 Micheal Jones의 실시간으로 얼굴을 탐지하는 작업이었다. 2001년에는 컴퓨터 칩이 느렸지만 거의 실시간으로 이미지에서 얼굴을 감지 할 수 있었고 2006년 5월 신문에 발표한 후 Fujifilm은 실시간 얼굴 탐지가 가능한 최초의 디지털 카메라를 출시하게된다.
기초 과학 연구에서 실제 세상에 응용까지 매우 빠른 인계였으며 어떻게 하면 물체를 더 잘 인식할 수 있을지 지속적으로 연구하고 있다. 1990년대 후반부터 2000년대 초반까지 가장 영향력 있었던 사고방식 중 하나는 feature 기반의 물체 인식이었다. SIFT feature라고 불리는 David Lowe의 작업이 있는데.

예를 들자면 정지신호가 있는데 문제는 이 정지신호를 다른 정지신호와 일치시키는 일은 매우 어려운데 바로 카메라의 각도, 시점, 조명 및 객체 자체의 고유한 변형으로 인해 그렇다. 하지만 관찰하던 중 객체에는 변화에 영향을 받지 않는 어떠한 특징이 있다는 사실에 영감을 얻게 되면서 객체 인식은 중요한 feature를 식별하고 유사 객체와 feature를 일치시키는 것으로 시작이 된다. 이는 전체 객체를 일치시키는 것보다 쉬운 작업이기 때문이다. 따라서 위 그림은 하나의 정지 표시로부터 SIFT 특징들이 식별되며 다른 정지 표지의 SIFT 특징들과 일치한다는 것을 보여주는 그림이다.
한 걸음 더 나아가 feature를 사용하여 전체론적(holistic) 장면을 인식하기 시작했다. 한 예로 'Spatial Pyramid Matching'이라 불리는 알고리즘이 있는데.

이 아이디어는 풍경이나, 부엌, 고속도로 등 어떤 장면 유형이든 상관없이 feature가 있고 그 장면이 무엇인지에 대한 단서를 제공한다는 것이다. 이 작업은 이미지의 다른 부분과 다른 해상도에서 feature를 가져와 feature discriptor에 넣고 그 위에 vector machine 알고리즘을 사용하는 것이다. 매우 유사한 연구가 인간 인지(human recognition)에 힘을 얻고 있다. 이러한 feature를 잘 정리하면 보다 현실적인 이미지로 인체를 구성하고 인식할 수 있는 방법을 모색하는 많은 작업을 수행할 수 있다. ("Histogram of gradients", "deformable part models"와 같은 영상 feature 방법이 있다.)
> feature descriptor : 유용한 정보를 추출하고 불필요한 정보를 버림으로써 이미지를 단순화하는 이미지 또는 이미지 패치 표현.
1960년대를 지나 21세기 초까지, 한가지 변화는 사진의 품질이다. 인터넷의 성장과 함께 디지털카메라는 computer vision을 연구하기 위해 더 좋은 데이터를 가지게 되었고 2000년대 초의 결과 중 하나는 computer vision 분야가 해결해야 할 중요한 feature 문제를 정의했다는 것이다. 물론 이것은 해결해야 할 유일한 문제가 아니지만 인식의 측면에서, 객체 인식(object recognition)을 해결하는 매우 중요한 문제이다. 지금까지 객체 인식에 대해서 계속 이야기하고 있는데. 스탠퍼드에서 2000년대 초반에 객체 인식의 진행 상황을 측정할 수 있는 벤치마크 데이터셋을 만들기 시작한다. 바로 가장 영향력 있는 벤치마크 데이트셋 중 하나인 "PASCAL Visual Object Challenge"이다. 20개의 객체 클레스들로 구성된 데이터셋이며 기차, 비행기, 사람, 고양이, 소 등이 있고 데이터셋의 범주당 수천에서 수만 가지의 이미지로 구성되며 field마다 testing set에 대해 테스트를 하고 진행 상황을 확인하는 알고리즘을 개발하게 된다.
여기 2007 ~ 2012년까지 보여주는 차트가 있는데. 벤치마크 데이터셋에서 이미지의 object 감지 성능이 꾸준히 증가하는 걸 볼 수 있듯. 많은 진전이 있을 즘에 Princeton에서 Stanford에 이르기까지 스스로에게 더 어려운 질문을 하기 시작한다. 즉 "과연 우리가 세상의 모든 것을 인식할 준비가 되어있는가?"이다.
Machine learning 알고리즘의 대부분은 graphic model, support vector machine 또는 AdaBoost인지 여부는 중요하지 않다. 교육 과정에서 지나치게 적합(overfit) 할 가능성이 높으며 일부 문제는 시작 데이터가 매우 복잡하다는 것이다. 복잡하게 되면 모델은 높은 차원의 입력을 가지는 경향이 있고, 많은 매개 변수를 필요로 한다. 충분한 교육 데이터(training data)가 없을 때. 과적합(overfiting)은 매우 빠르게 일어나며 일반화(generalize) 하기가 어렵다. 두 가지 이유에 의해 동기부여가 되는데 하나는 세계의 모든 객체 인식하고 싶다는 것이고 다른 하나는 [machine learning으로 돌아와서] 과적합의 병목 현상을 극복하는 것이다. 그렇게 ImageNet이라는 프로젝트를 시작하게 된다.
ImageNet

ImageNet 프로젝트는 시각적 객체 인식 소프트웨어 연구에 사용하도록 설계된 대형 시각적 데이트베이스이다. 1400만 개가 넘는 이미지 URL이 ImageNet에 의해 손으로 주석 처리되어 어떤 물체가 그려지는지 알려준다. 적어도 백만개의 이미지에서 bounding box가 제공되며 ImageNet에는 2만 개 이상의 모호한 범주가 있다.
Bounding box: bbox라고도 하며, 2개의 경도와 2개의 위도로 정의되는 영역이다.
우리는 세상에 존재하는 객체에 대해 찾을 수 있는 가능한 가장 큰 데이터셋을 만들고자 했으며 데이터셋을 사용하여 훈련하고 벤치마킹을 했다. 따라서 약 3년의 기간 동안 진행된 정말 어려운 프로젝트였다. 기본적으로 'WordNet'이라 부르는 수만 개의 object classes로 구성된 사전을 사용해서 정리된 수십억 개의 이미지를 인터넷에서 다운로드하는 걸 시작으로 한다.
워드넷(WordNet): 영어의 의미 어휘목록이다. 영어 단어를 'synset'이라는 유의어 집단으로 분류하여 간략하고 일반적인 정의를 제공하고, 이러한 어휘목록 사이의 다양한 의미 관계를 기록한다. 워드넷은 심리학 교수인 조지 A. 밀러가 지도하는 프린스턴 대학의 인지 과학 연구소에 의해 만들어졌고 유지되고 있다. 개발은 1985년에 시작되었다.
그런 다음 clever crowd engineering trick을 사용해야 했는데. Amazon Mechnical Turk platform을 사용해서 각각의 이미지를 sort, clean, label 했다. 최종 결과는 22,000개의 카테고리로 정리된 150만에서 400만 이상에 해당하는 물체와 장면에 대한 ImageNet으로 이것은 매우 거대하며(gigantic), 아마 그 당시에 인공지능 분야에서 만들어진 가장 큰 데이터셋일 것이다. 그리고 객체 인식에 대한 알고리즘을 다른 단계(phase)로 나아가도록 했다.
특히나 중요한 것은 "어떻게 과정을 벤치마크 할 것인가"인데. 2009년을 시작으로 ImageNet 팀은 국제적인 대회를 열었고 (ImageNet Large-Scale Visual Recognition Challenge)이 대회를 위해서 더욱 강화된 test set(140만 개의 객체와 1,000개의 object classes로 구성된)을 준비했다. 그리고 이것은 computer vision 알고리즘의 결과를 위해 이미지 분류 인식을 테스트 하기 위함이다.

그리고 예제 사진처럼 만약 알고리즘의 결과가 5개의 label을 출력할 수 있고 상위 다섯 개의 label이 올바른 객체를 포함하고 있다면 '성공'이라 부른다.

ImageNet challenge 이미지 분류 결과로 (2011 ~ 2016년) 좋은 소식은 에러율이 지속적으로 줄어들고 2012년에 큰 폭으로 줄어드는데 비록 이미지 인식에(이번 강의에서 배우게 될) 대한 모든 문제를 풀지는 못 했지만 엄청난 진전을 이루었으며 실세계 응용 프로그램이 ImageNet 도전과제에서 사람과 **(여기서 사람이란 한 명의 스탠포드 대학 박사학위 학생인데 마치 대회에 참여하는 컴퓨터인 것처럼 몇 주간 일을 했다.)** 동등한 수준으로 오류율을 좁히는 데는 몇 년 밖에 걸리지 않았다. 그리고 특별히 주목해야 할 순간은 2012년인데.
처음 2년 동안은 오류율이 25%에 머물렀던 것이 2012년에는 10%나 떨어져 16%가 되었다. 물론 지금은 더 좋지만 그만한 감소율은 significant하고 그 해 우승을 차지한 알고리즘은 CNN( convolutional neural network) 모델인데 다른 알고리즘을 다 물리치고 ImageNet Challenge의 우승을 차지했다. 이 강의는 deep learning 이라고도 불리는 CNN모델에 대해 심층적으로 다루며 이 모델들이 무엇인지, 무엇이 좋은지, 그리고 이 모델의 최근 진행 상황은 무엇인지를 공부할 것이다. 역사가 만들어진 곳은 2012년 CNN 모델인데. 자연어 처리 및 음성 인식과 같은 다른 여러 자매 분야와 함께 computer vision에서 좋은 발전을 이루는데 막대한 역량과 능력을 보여주었기 때문이다.
Vision Recognition
CS213n 강의에 대해서 조금 더 말하자면, visual recognition에서 가장 중요한 문제 중 하나인 image classification을 다룬다. Image classification의 구조는 알고리즘이 이미지를 보고 고정된 집합의 범주에서 선택하여 해당 이미지를 분류하는 것인데. 이것은 제한적이거나 인위적인 설정으로 보일 수도 있지만, 사실 꽤 일반적이다. 그리고 산업계와 학계 그리고 많은 다양한 분야에서 적용될 수 있는데. 예를 들어, 음식을 인식하거나, 음식의 칼로리를 인식하거나 세상의 예술품, 제품들을 인식하는데 적용할 수 있다. 따라서 이 상대적으로 기본적인 영상 분류 도구는 그 자체적으로 매우 유용하며 여러 가지 용도로 전 세계에 적용할 수 있다.
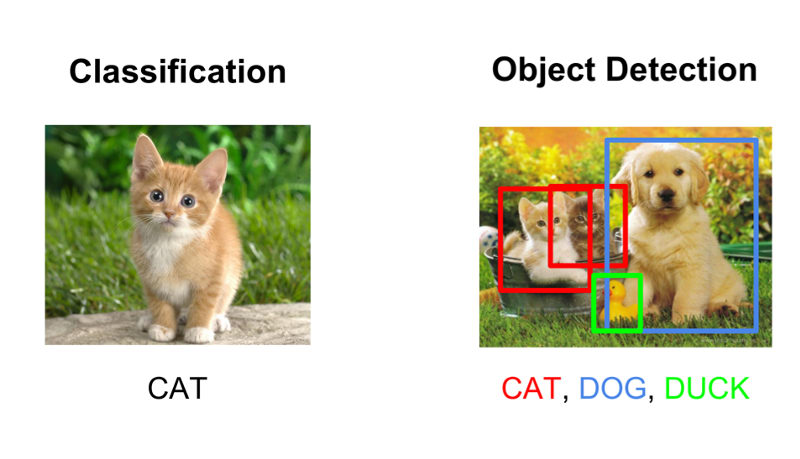
이 과정에서는 image classification을 위해 개발한 많은 도구를 기반으로 하는 몇 가지 visual recognition 문제에 대해서도 설명할 것인데. Object detection, image captioning과 같이 image classification과 관련된 여러 가지 visual recognition 문제를 다룰 것이다. Object detection 구조는 고양이, 개, 말 그 외 전체 이미지를 분류하는 것과는 조금 다른데. 대신 bounding box를 그리고 여기 고양이가 있고 여기 개가 있고 저기 배경에 자동차가 있다며 이미지 안에 있는 객체에다가 박스를 그려서 설명하는 것이다.
또한 image captioning도 다룬다. 이미지가 주어지면 시스템은 이미지를 설명하는 자연어 문장을 만들어야 하는데, 정말 어렵고 복잡하며 다른 문제인 것 같지만, 이미지 분류를 위해 개발된 많은 도구들이 다른 문제에서도 재사용 된다.
CNN은 사물 인식의 중요한 도구가 되었는데, 앞서 ImageNet Challenge 맥락에서 언급했지만, 최근 몇년간 이 분야의 발전을 이끈 것 중 하나는 CNN(혹은 convnets / deep learning이라 불리는)의 채택이었다.
ImageNet
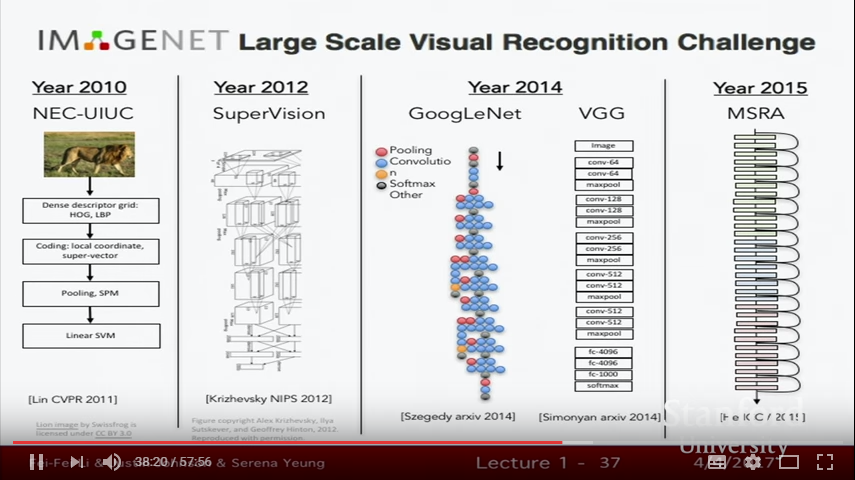
지난 몇년간 ImageNet 챌린지에서 우승한 알고리즘을 살펴보자. 2011년 Lin CVPR 2011을 보면 이 방법은 여전히 계층적인데, 다중 레이어로 구성되어 있다. 그런 다음 일부 local invariances 요소를 계산하고 일부는 pooling 한 다음 여러 계층의 처리 과정을 거쳐 최종적으로 이 resulting descriptor를 linear SVN에 제공한다. 여기서 주목할 것은 이것이 여전히 계층적이라는 것이다. 우리는 여전히 edges를 감지하며. 아직도 불변성(invariance)에 대한 개념을 가지고 있다. 그리고 많은 직관(intuition)들이 CNN으로 넘어갈 것이다.
AlexNet
그러나 놀라운 순간은 2012년 Jeff Hinton's의 토론토 그룹이 그의 PhD 학생이었던 Alex Krizhevsky와 Ilya Sutskever와 함께 AlexNet이라 알려 진(그 후 Supervision이라고 불린다. 2012년 ImageNet 대회에서 좋은 성적을 거두었다.) 7개의 층을 가진 CNN을 만들었다는 것이다.
그때부터 매년 ImageNet의 우승자는 신경망을 사용했으며. 그리고 이 신경망 트렌드는 매년 점점 더 깊어져 가고 있다. AlexNet은 7~8계층의 신경망이지만 정확히는 어떻게 계산하느냐에 따라 다르긴 하다. 2015년에는 훨씬 더 깊은 망을 가지게 되었는데 구글에서 만든 GoogleNet 그리고 VGG가 있다. VGG는 당시 Oxford에서 19개 층으로 구성된 네트워크이다. 그러고 2015년 정말 미쳤는데 당시 152개의 층을 가진 Microsoft Reserach Asia에서 만든 Residual Networks라는 녀석이 있다. 그리고 나서 200개까지 층이 올라가며 조금 더 성능이 좋아지게 되지만 GPU 메모리 성능이 부족하게 된다. 이 부분은 나중에 다시 이야기하도록 하고, **여기서 중요한 것은 2012년에 이런 획기적인 순간이 있었다는 것인데.** 그 이후로 알고리즘을 더 잘 조정하고 다루기 위해서 많은 노력을 해오고 있다.
CNN에 있어 혁신적인 순간은 2012년 ImageNet 챌린지에서 좋은 성과를 냈을 때였지만, 이 알고리즘은 사실 그전부터 꽤 오랫동안 존재해 왔다. 그래서 이 CNN에 있어 기반을 다진 작업은 90년대에 그 당시 Bell 연구실에 있던 Jan LeCun과 그 동료들로부터 만들어졌다.

1998년에 숫자를 인식하기 위해 CNN을 만들게 되었는데 이것을 배치하여 우체국의 손으로 쓴 수표나 주소를 자동으로 인식할 수 있기를 원했다. 그리고 이 CNN은 이미지의 픽셀을 받아서 숫자인지 혹은 문자인지 혹은 그 외의 것들을 분류할 수 있게 되었다. 이 망의 구조는 2012년에 사용된 AlexNet의 구조와 매우 유사한데. 여기 보이는 것처럼 우리는 이 원시 픽셀을 입력받으며 완전히 연결된 계층(fully connected layers)과 함께 많은 콘볼루션 계층과 sub-sampling을 가지고 있다. 이 모든 것들은 나중에 더 자세히 설명하게 될 것이지만, 두 그림은 보기만 해도 꽤 유사해 보인다.
> Sub-sampling :
> Sampling :

Why these algorithms are suddenly become popular?
2012년에 만들어진 이 설계구조는 1990년의 망과 많은 구조적 유사점을 공유하는데. "그렇다면 이 알고리즘은 왜 갑자기 수면 위로 올라오게 되었는가?"라고 의문이 들 텐데. 90년대 이후 변한 몇 가지 중요한 혁신들이 있다. 하나는 컴퓨터의 계산능력인데 (Thanks to Moore's law) 우리는 매년 더 빨라진 컴퓨터를 사용하고 있다. 조금 투박한 측정이긴 하지만 컴퓨터 칩에 있는 트랜지스터의 수만 보더라도 90년대와 오늘날 사이에 몇 배나 커졌기 때문이다. 또한 GPU의 등장이 있는데, GPU의 super parallelizable 한(병렬 처리가 매우 잘 되는) 이유로 결국엔 계산 집약적인 CNN 모델을 처리하기 위한 완벽한 도구가 되었다. 따라서 더 많은 계산을 처리할 수 있게 되면서 연구원들로 하여금 더 큰 아키텍처와 대형 모델을 탐색할 수 있게 하였다. 어떤 경우에는 모델 크기를 늘리면서도 이런 고전적인 접근 방식과 고전적인 알고리즘을 사용하는 것이 잘 작동하는 경향이 있다. 따라서 계산을 증가시키는 아이디어는 deep learning의 역사에 있어서 매우 중요하다.
현재와 90년대를 바꾼 두 번째 핵심적인 혁신은 데이터라고 생각한다. 이런 알고리즘들은 데이터에 매우 굶주려 있는데, 우리는 많은 labeled image와 픽셀들을 공급하여 알고리즘이 잘 작동하도록 해야 한다. 그리고 90년대에는 많은 양의 데이터를 사용할 수 없었으며 크고 다양한 데이터 셋을 수집하는 것은 매우 어려웠다. 인터넷이이나 Mechanical Turk와 같은 도구들이 널리 사용되기 전이었기 때문이다.
> Mechanical Turk : 18세기 가짜 체스기계, 본문에서는 인공지능을 의미하는 거 같음.
그러나 2010년대에는 PASCAL이나 ImageNet과 같은 90년대에 출시된 데이터셋보다 훨씬 더 큰 고품질의 labled 데이터셋이 존재하고 있다. 그리고 이런 많은 데이터셋 덕분에 더 높은 용량의 모델로 작업하고 이 모델을 현실 속 문제에서 실제로 잘 작동하도록 훈련할 수가 있다. 그러나 여기서 중요한 비중을 차지하는 것은 CNN인데. 뭐랄까 비록 지난 몇 년 동안 갑자기 나타난 화려하고 새로운 것처럼 보이긴 하지만 실제로는 그렇진 않다. 그리고 이런류의 알고리즘은 오랫동안 독자적으로 존재해 왔는데, Computer vision에서 언급할만한 또 다른 일은 사람처럼 보일 수 있는 기계를 만드는 일이다.
사람은 실제로 visual system으로 많은 놀라운 일들을 할 수 있는데, 우리의 visual system은 보다 훨씬 강력하기 때문에 세상을 돌아다니면 그저 객체에 박스나(bounding box) 그려서 이게 고양이고 이게 강아지야 하는 것보다 더 많은 것을 할 수 있다.
이 분야에서 나아갈 때, 해결해야 할 많은 도전과 문제들이 있다고 생각하며 야심찬 문제를 해결하기 위해 알고리즘을 계속 개발할 필요가 있다. 이것에 대한 몇 가지 예로 오래된 아이디어로 돌아가면, 이미지 전체에 레이블을 지정하는 대신 이미지의 모든 픽셀을 이해하고 싶다는 것이다. 이것이 무엇을 하는지 혹은 무엇을 의미하는지 등. 이 아이디어는 나중에 살펴보도록 하고.
전 세계를 재구성하는 3차원을 이해하는 아이디어가 분명히 존재할 것인데 아직은 해결되지 않은 문제라고 생각한다. 우리가 상상할 수 있는 수많은 작업들이 있는데 예를 들어 활동 인식의 경우, 어떤 사람이 어떤 활동을 하는 영상을 받았다면 그 활동을 인식하는 가장 좋은 방법이 무엇일까? 하는 것이다. 이것은 꽤 어려운 문제임이 분명하며. 앞으로 증강현실, 가상현실 그리고 새로운 기술이나 센서가 출시됨에 따라 새롭고 흥미롭고 또 어려운 문제를 생각해 낼 것이다.

이것은 visual genome이라 불리는 한 예인데(Johnson이 본인 연구실에서 연구한 결과) 현실 세계의 이런 복잡한 것들을 포착하고자 한다. 단순히 상자를 설명하는 것보다는 이미지 정체성뿐만 아니라 객체의 관계, 속성 그리고 장면에서 발생하는 동작을 포함하며 의미론적(semantically)으로 관련된 개념 전체를 그래프로 설명하는데. 이러한 묘사는 간단한 분류를 할 때에 우리로 하여금 시각 세계의 풍부함(richness) 중 일부를 포착할 수 있도록 해준다.
이 시점에서 결코 표준적인 접근법은 아니지만 이 바닐라 이미지 분류 설정에서는 "시각 시스템이 할 수 있는 일은 너무나도 많다."같은 느낌을 준다.
컴퓨터 소프트웨어나 (컴퓨터 하드웨어 또는 알고리즘과 같은) 컴퓨터 관련 시스템에서 기존 형태에서 사용자 정의되지(customized) 않은 것을 "바닐라"라 부르는데, 이는 사용자 정의나 업데이트 없이 사용된다는 의미이다.

또 다른 흥미로운 일은, 실제로 Fei-Fei 교수의 대학원 시절, 그곳 고문들과 함께 박사과정을 밟았을 때인데. 이 프로그램에서 사람들을 대상으로 위 사진을 0.5초 동안 보여주었다. 매우 짧은 시간의 노출에도 사람들은 이미지의 전체적인 이야기를 들려주는 긴 설명을 쓸 수 있었으며 그리고 이것이 한 사람이 겨우 0.5초간 이미지를 보고 말한 것이라는 것은 꽤나 놀라운 일이다. 그 사람은 이 이미지가 일종의 게임이나 싸움이라고 말했으며, 두 그룹의 남자들이 있고, 왼쪽에 있는 남자가 뭔가를 던지고 있으며 야외에 잔디 같은 느낌이 든다고 했다. 아마 이 사진을 더 길게 보았다면, 이 사람들이 누구인지, 왜 거기서 게임을 하는지 대한 소설도 쓸 수 있었을 것이다. 그들의 외부 지식과 경험으로부터 무언가를 계속해서 얻을 수 있었을 것인데. 이것은 어떤 의미에서 컴퓨터 비전의 성배(holy grail)라고 할 수 있는데. 일종의 매우 풍부하고 깊은 방법으로 이미지의 내용을 이해하는 것이다.
holy grail : 큰 의의를 위해 추구하는 목적, 찾거나 얻기가 극히 어려운 것.
그러나 지난 몇 년 동안 해왔던 이 분야에서의 엄청난 진전에도 불구하고 우리는 여전히 이 성배를 달성하기까지 많이 남았다고 생각한다. 이 아이디어의 좋은 예가 되는 또 다른 이미지를 Andrej Karpathy's의 블로그에서 찾을 수 있는데.

이는 정말 놀라운 사진이며 꽤 재밌는 사진이라고 생각을 한다. 그럼 왜 재미있는 사진인가? 우리는 한 사람이 저울에 서있는 것을 알고 있으며, 사람들이 때대로 자신의 체중에 신경 쓰고, 체중을 측정하는 것을 알고 있다. 그리고 그 뒤에 있는 다른 사람이 자신의 발을 체중계에 올려놓고 있고 체중계가 작동하는 방식 때문에 저울은 더 늘어난 수치를 보여고 있다. 게다가 우리는 이 사람이 그냥 아무 사람이 아닌 당시 미국 대통령이었던 버락 오바마이고, 대통령은 이런 식으로 동료들에게 장난을 하지 말아야 할 존경받아야 하는 정치인이라는 것도 알고 있다. 그리고 배경에 뒤에서 웃고, 미소 짓는 사람들이 있다는 것을 알고 있고, 그들이 그 장면에 대해 무언가 이해하고 있다는 것을 알고 있다. 우리는 그들이 앞사람을 보고 있는 오바마 대통령은 존경받아야 하는 사람이라는 것을 알고 있다는 사실을 이해하고 있다. 이건 정말 엄청난데, **이 사진에는 정말 많은 일들이 일어나고 있다는 것이다.**
오늘날의 컴퓨터 비전 알고리즘은 이미지에 대한 진정한 깊은 이해이다. 그래서 이 분야에서의 엄청난 진전에도 불구하고, 여전히 갈 길이 멀다고 생각을 하고 있다. 연구원으로써 정말 흥분되는 일이라고 생각을 하는데 왜냐하면 앞으로 나아가야 할 정말 흥미롭고 멋진 문제들을 많이 기다리고 있기 때문이다. 그리고 이 시점에서 컴퓨터 비전이 정말 흥미롭고, 매우 유용할 수 있고, 다양한 방법으로 세상을 더 좋은 곳으로 만들 수 있다는 사실을 여러분들에게 비교적 잘 전달을 했으면 한다. 컴퓨터 비전은 의료 진단, 자율 주행 차, 로봇 공학 등 다양한 분야에서 적용될 수 있으며 인간의 지능을 이해하는 핵심적인 개념과도 연결이 된다. 그래서 컴퓨터 비전이 환성적이며 놀랍고 흥미로운 분야라고 생각을 한다.
'IT 관련 공부' 카테고리의 다른 글
| Python으로 Telegram 챗봇 만들기(4) - 네이버 실시간 인기검색어 받아오기 (0) | 2019.08.22 |
|---|---|
| Python으로 Telegram 챗봇 만들기(3) - 네이버 영화순위 받아오기 (0) | 2019.08.22 |
| Python으로 Telegram 챗봇 만들기(2) - 네이버 날씨 받아오기 (0) | 2019.08.22 |
| Python으로 Telegram 챗봇 만들기(1) - 봇 생성과 멜론차트 받아오기 (3) | 2019.08.22 |
| CS231n Lec2(번역) (0) | 2019.04.12 |
- Total
- Today
- Yesterday
- 청도맥주
- Machine Learning
- CS231n
- 텔레그램
- chatbot
- 챗봇
- 삼성생명현장실습
- 진취덕
- 텔레그램 챗봇
- 칭다오
- Python
- 예스진지
- Qingdao
- 청도맥주축제
- 금사탄
- 대만여행
- AI그림 그리기
- 파이썬
- 스펀
- 샹산
- 청도여행
- web ui
- ai그림
- image classification
- 85도씨커피
- stable diffusion
- 챗본만들기
- 청도맥주박물관
- 텔레그램 봇
- telegram
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |