
티스토리 뷰
혼자 공부할겸 영상 보면서 번역한 거라 오역이 (많이) 있을 수 있음
Welcome to lecture two of CS231N.
수업 전에 몇 가지 안내하는 내용이므로 안 읽어도 무관함
지난 강의에서 우리는 컴퓨터 비전, 역사, 수업의 개요가 무엇인지에 대한 큰 그림을 보았고 오늘은 처음으로 세부 사항에 들어가서 학습 알고리즘의 일부가 실제로 실제로 어떻게 작동하는지 훨씬 더 깊이 알게 될 것입니다.
지난 첫 강의는 일종의 비전(Vision)에 대한 가장 큰 그림이었고 이 수업의 대부분의 강의는 보다 세부적인 방향으로 이루어질 것이며, 다양한 알고리즘의 특정 메커니즘에 훨씬 더 집중할 것입니다. 오늘 우리의 첫 번째 학습 알고리즘을 보게 될 것이지만 그전에 몇 가지 행정 문제에 대해 이야기하고 싶습니다.
1. 첫 번째는 피아자(Piazza)인데
어제 보니 피아자에 500여 명이 등록한 것처럼 보였는데. 그 말은 즉, 아직도 수백 명이 등록 하지 않았다는 것입니다. 우리는 피아자가 학생들과 스태프들 간의 주 의사소통 수단이 되기를 정말로 원하며 프로젝트 아이디어, 중간 출석 또는 포스터 세션 출석과 같은 질문들은 반드시 피아자에서 확인해야 합니다. 그리고 모든 TA들이 확인하기 때문에 피아자에 있는 질문들은 답변을 더 빨리 얻을 수 있습니다.
그리고 코스 목록에 있는 이메일로 메일을 보내면 섞이기 쉽습니다. SCPD 학생들 중 일부가 Piazza에 등록하는 데 약간의 어려움을 겪고 있음을 알게 되었는데. SCPD 학생들은 반드시 @stanford. edu 이메일 주소를 받도록 되어있기 때문에 이메일 주소를 받으면 스탠퍼드 이메일을 사용하여 피아자에 로그인할 수 있고 아마 SCPD를 듣는 학생들이 지금 방에 앉아있는 사람들에게는 영향을 주진 않을 것입니다.
2. 다음 문제는 과제 1에 관한 것인데.
과제는 오늘 오후 언젠가는 업로드됩니다만 밤 잠자리에 들기 전에는 올라갈 것을 약속합니다. 그러나 당장 작업하기를 원한다면 작년 버전의 과제물을 보면 되는데 내용은 거의 동일합니다. 예를 들어 Python 2.7보다는 Python 3에서 작동하도록 업그레이드하는 것과 같이 조금 바꾸어 놓았습니다만 이러한 사소한 외관상의 변화들 중 일부는 여전히 작년과 동일할 것입니다.
따라서, 이 과제에서 여러분은 이번 강의에서 배울 자신 만의 K-최근접 이웃 알고리즘(KNN, K-Nearest Neighbor classifier)을 구현할 것이며 SVM과 Softmax를 비롯하여 간단한 2층 신경망(Two-layer neural network)을 비롯한 몇 가지 선형 분류기도 구현할 것인데 다음 강의에서 이 모든 내용을 다룰 것입니다. 그리고 모든 과제는 Python과 NumPy를 사용합니다.
만약 Python 또는 NumPy에 익숙하지 않을 경우 코스 웹 사이트(http://cs231n.github.io/python-numpy-tutorial/)에서 찾을 수 있는 튜토리얼을 작성하며 학습하시고 이건 정말 중요한데 NumPy는 정말 효율적인 벡터화 연산을 통해서 여러분이 코드 몇 줄로 많은 계산을 수행할 수 있도록 도와줄 것이기 때문입니다. 따라서 수치 계산 및 기계 학습의 거의 모든 측면과 이러한 벡터화된 작업을 효율적으로 구현하는 것과 같이 모든 면에서 매우 중요합니다.
그리고 첫 번째 과제에서 이것으로 많은 연습을 하게 될 것입니다. 따라서 Matlab이나 NumPy 또는 다른 유형의 벡터화된 텐서 계산에 대해 많은 경험이 없는 사람들은 과제를 일찍부터 살펴보고 튜토리얼을 주의 깊게 읽기를 권장합니다.
3. 제가 이야기하고자 하는 또 다른 사항은
Google Cloud가 공식적으로 지원된다는 걸 알리게 되어 기쁩니다. Google Cloud는 Amazon AWS와 유사한데. 클라우드에서 가상 시스템을 시작할 수 있으며 이러한 가상 머신에서 GPU를 사용할 수 있습니다. Google Cloud를 사용하여 과제를 처리하는 방법에 대한 튜토리얼을 작성하고 있는데. 그러나 여기서는 단지 약간의 이미지를 다운로드할 수 있으며, 클라우드에서 이러한 인스턴스 중 하나에 대한 할당 작업을 매우 원활하게 수행할 수 있다는 것을 의미합니다.
Google에서 매우 관대하게 이 수업을 지원했기 때문에 Google의 쿠폰 크레디트를 무료로 사용할 수 있도록 각 쿠폰을 배포 할 겁니다. 따라서 숙제 및 프로젝트에 자유롭게 사용할 수 있습니다.
오늘 나중에 피아자에 자세한 내용을 게시할 것인데. 몇 가지 질문이 있어 이야기를 하자면 "개인 노트북을 사용할 수 있을까요?" "Corn에서 실행해야 합니까?" 등등 그래서 대답은 Google Cloud에서 실행할 수 있으며 이를 위해 우리가 쿠폰을 제공할 것이라는 것입니다. 쨋든 이것들이 내가 오늘 말하고 싶은 중요한 행정 문제들이며 그럼 이제 수업내용을 자세히 살펴보겠습니다.
Image Classification pipeline
컴퓨터 비전에서 핵심 과제인 이미지 분류 작업에 대해 조금 이야기를 나누었는데. 이것은 우리가 수업 과정 전반에 걸쳐 집중해야 하는 것이며 정확히는 "이 이미지 분류 작업을 어떻게 해야 할까?"인데, 좀 더 구체적으로 말하자면 이미지 분류를 할 때 시스템은 일부 입력 이미지를 수신하고 시스템은 미리 결정된(predeterminded) 범주(categories) 또는 레이블(labels)의 집합을 인식하기 때문에 개, 고양이, 트럭, 비행기와 같은 카테고리 레이블이 있을 수 있는데, 컴퓨터의 역할은 그림을 보고 고정된 카테고리 레이블(fixed categery label) 중 하나에 할당하는 것입니다.

이것은 매우 쉬운 문제처럼 보이는데, 사실 우리 두뇌에 있는 많은 시각 시스템이 이러한 일종의 시각적 인식 작업을 하기 위해 하드웨어적으로 내장되어(hardwired) 있기 때문에 그렇습니다. 하지만 사실 컴퓨터에겐 정말로 어려운 문제인데, 컴퓨터가 이미지를 볼 때 실제로 무엇을 보는지에 대해 생각해 보면, 컴퓨터는 우리가 고양이를 보았을 때처럼 고양이에 대한 전체적인 아이디어(holistic idea)을 얻지 못하기 때문입니다.

실제로 컴퓨터는 이 거대한 수의 격자로 이미지를 표현하는데, 이미지는 마치 800 x 600 픽셀과 같을 수 있고 각 픽셀은 세 개의 숫자로 표현되며 그 픽셀에는 빨강, 녹색 및 파랑 값을 제공합니다. 따라서, 컴퓨터에게 이것은 단지 거대한 숫자 격자일 뿐이며 수천, 또는 아주 많은 수의 배열이지 고양이를 추출하는 것은 매우 어렵습니다.
Semantic Gap
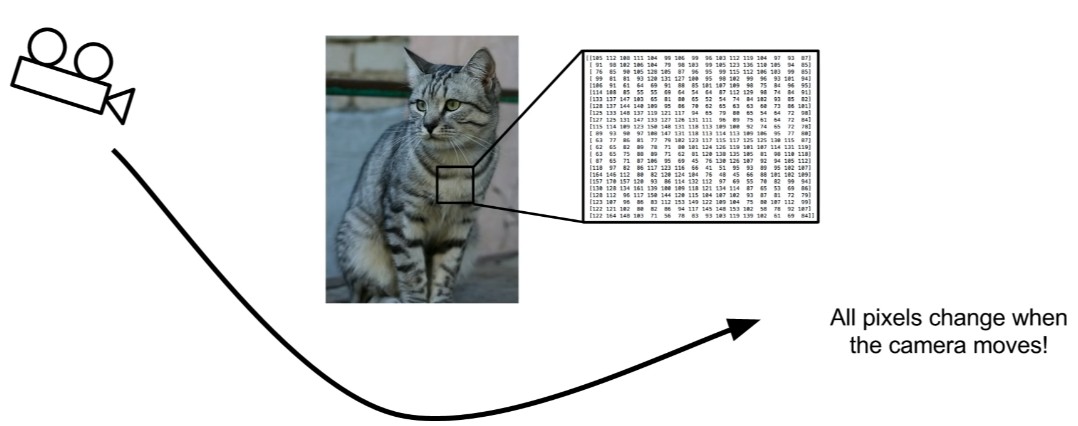
그래서 우리는 이 문제를 의미적 차이(semantic gap)라고 부르는데. 고양이 또는 고양이의 레이블의 개념은 이 이미지에 지정하는 의미 레이블(semantic label)이며 고양이의 의미 개념(semantic idea)과 컴퓨터가 실제로 보고 있는 픽셀 값 사이에 큰 차이가 있다. 그리고 이것은 매우 어려운 문제인데 왜냐하면 우리는 이 픽셀 그리드가 완전히 바뀔 수 있는 아주 작고 미묘한 방법으로 그림을 변경할 수 있기 때문입니다.
예를 들어, 결코 일어나지는 않겠지만 위와 같은 고양이를 가지고 이 고양이가 얌전히 앉아서 조금도 씰룩 이거나 근육을 움직이지 않는 상태로 우리가 카메라를 다른 쪽으로 이동시킨다면 모든 단일 그리드와 모든 단일 픽셀들 즉, 이 커다란 그리드 속의 숫자들은 완전히 달라질 것입니다. 그러나 어쨌든, 고양이는 여전히 같은 고양이라는 것이며 그리고 우리의 알고리즘은 이것에 견고(robust) 해야 합니다.
Challenges: Illumination

그러나 관점(viewpoint)만이 문제가 아닌데 또 다른 문제는 조명이다. 장면마다 다른 조건의 조명이 발생할 수 있으며 고양이가 매우 어둡거나 변덕스러운 장면에 등장하든, 매우 햇볕이 잘 드는 장면도 여전히 고양이 이며 우리 알고리즘은 이 사실에 견고할 필요가 있다.
Challenges: Deformation

객체는 변형될 수 있는데. 나는 어쩌면 고양이는 우리가 볼 수 있는 가장 변형 가능한 동물 중 하나라고 생각한다. 그리고 고양이는 실제로 다양한 자세를 취하거나 위치를 선점할 수 있으며 우리의 알고리즘은 이러한 종류의 변형에도 역시 견고해야 합니다.
Challenges: Occlusion

우리가 고양이 일부를 보거나, 그냥 얼굴만 보거나, 극단적으로 소파 쿠션 아래에서 꼬리만 볼 수 있는 것처럼 폐색(occlusion) 문제가 있을 수 있습니다. 그러나 이러한 경우에 사람은 고양이가 고양이라는 사실을 깨닫기가 매우 쉽다는 것입니다. 그리고 꽤 어렵겠지만 우리의 알고리즘 또한 반드시 이 사실에 견고해야 한다는 겁니다.
Challenges: Background Clutter

어쩌면 고양이의 전경 객체(foreground object)가 실제로 배경과 매우 비슷하게 보일 수 있는 배경 교란(background clutter)의 문제가 있을 수 있으며 이것이 우리가 처리해야 할 또 다른 문제입니다.
Challenges: Intraclass variation

또한 클래스 내부 변화(Intraclass variation) 문제는 고양이들이 다양한 모양과 크기, 색상 및 연령대로 나타날 수 있기 때문에 고양이(cat-ness)에 대한 이 개념이 사실상 다양한 시각적 모습을 많이 포함하고 있습니다. 따라서 우리의 알고리즘은 이러한 다양한 변형을 모두 처리해야 합니다.
따라서 이 문제는 진짜 정말로 도전적인 문제인 반면 우리 뇌의 많은 부분이 이런 문제를 다루기 위해 특별하게 조정되었기 때문에 이것이 얼마나 쉬운지를 잊기 쉽지만 우리의 컴퓨터 프로그램이 고양이뿐 아니라 우리가 상상할 수 있는 어떠한 객체 카테고리에 있든지 이 모든 문제를 다루기를 원한다면 이것은 매우 도전적인 문제일 것입니다. 그렇지만 내 입장은 사실 기적적이게도 어떻게든 모두 되리라 생각합니다.
그러나 실제로 작동하는 것뿐만 아니라 일부 제한적인 상황에서는 인간의 정확도와 매우 유사하게 동작하는데, 그러면서도 수백 밀리 초 밖에 걸리지 않습니다. 그러니 이것은 꽤 놀랍고도 엄청난 기술입니다. 그리고 나머지 수업 과정에서 어떠한 발전이 이 일을 가능하게 했는지 알 수 있게 될 것입니다.
An Image classifier
#An image classifier
def classify_image(image):
# Some magic here?
return class_label
#Unlike e.g. sorting a list of numbers,
#no obvious way to hard-code the algorithm for
#recognizing a cat, or other classes.이제 이미지 분류자(Image classifier)를 작성하기 위한 API가 무엇인지 생각해보면, 앉아서 파이썬으로 이와 같은 메서드를 작성하려고 시도할 수 있을 것입니다. 이미지를 찍은 다음 마법적인 처리를 하고, 결국에 클래스 레이블을 출력하여 이게 고양이나 개 또는 기타 등등이다 라는 결과를 내게끔 말이죠.
그러나 이것을 수행할 분명한 방법은 없습니다. 만약 알고리즘 수업을 듣는다면 우리가 할 일은 숫자를 정렬하거나 볼록 껍질(Convex hull)을 계산하거나 RSA 암호화(RSA encryption)와 같은 작업을 수행하여 일어날 수 있는 모든 단계를 열거하여 이 작업이 동작하도록 알고리즘을 작성할 수 있을 것입니다.
볼록 껍질(Convex hull) : 2차원 유클리드 좌표에서 어떤 점들의 집합으로 만든 다각형이 다른 모든 점들을 포함하는 점들의 집합을 말한다.
그러나 객체를 인식하거나, 고양이 혹은 이미지를 인식하려고 할 때, 이러한 객체를 인식하는 방법에 대해 직관적으로 이해할 수 있는 명확한 알고리즘은 없습니다. 다시 한번 말하지만, 이것은 매우 어려운 도전이고, 만약 당신의 프로그래밍 첫날에 이 기능을 쓰고 있어야만 한다면, 대부분의 사람들은 곤경에 처할 것이라고 생각합니다.
Attempts have been made
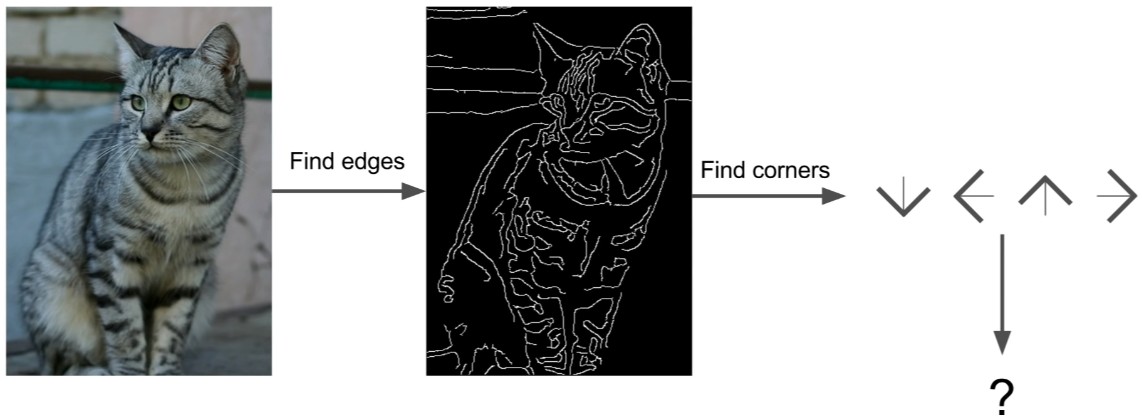
그렇긴 해도, 사람들은 분명 다른 동물을 인식하기 위한 하이엔드 코딩 규칙을 작성하려는 명백한 시도를 했고 따라서 우리는 강의 마지막에 이 부분을 조금 다룰 것입니다. 어쨌거나 고양이가 귀와 눈과 입과 코를 가지고 있다는 것인데. 우리는 Hubel과 Wiesel을 통해, 가장자리(edges)가 시각적 인식(visual recognition)에 있어서는 꽤 중요하다는 것을 알고 있습니다.
그래서 우리가 시도할 수 있는 한 가지는 이 이미지의 가장자리(edge)를 계산 한 다음 모든 모서리와 경계선을 분류하는 것이다. 그리고 아마 이런 식으로 3 개의 선이 만난다면 그것은 모퉁이(corner)가 될 것이고, 그리고 귀 같은 경우에는 여기 모퉁이 하나, 저기 모퉁이 하나, 또 다른 모퉁이 하나가 있으면 그 다음에는 고양이를 인식하기 위한이 명시적 규칙 집합(explicit set of rules)이 기록되게 되는 겁니다.
하지만 이것은 잘 작동하지 않는 것으로 밝혀졌습니다. 첫째, 부서지기가 아주 쉽습니다. 둘째, 예를 들어, 만약 여러분이 다른 물건 범주로 다시 시작하고 싶다면, 고양이는 신경 쓰지 말고, 트럭이나 개, 물고기 같은 것에 대해 하고 싶다면, 여러분은 모든 것을 다시 시작할 필요가 있습니다. 따라서, 이것은 실제로 확장 가능한 접근법(scalable approach)이 아니며 우리는 세계의 모든 다양한 물체들로 자연스럽게 확장되는 이러한 인식 작업을 위한 알고리즘이나 어떤 방법을 고안 해내고자 합니다.
Data-Driven Approach

그래서 이 모든 것을 가능하게 하는 통찰력은 데이터 기반 접근방식(Data-driven approach)에 대한 아이디어인데. 앉아서 손으로 지정된(hand-specified) 규칙을 만들어 정확하게 무엇이 고양인지, 생선인지 혹은 우리가 가진 어떤 것인지에 대해 작성하는 대신, 인터넷에서 고양이, 비행기, 사슴과 같은 여러 가지 다른 데이터 셋(data set)을 수집하는 겁니다.
그리고 구글 이미지 검색이나 그와 유사한 도구를 사용하여 이러한 다양한 범주의 예를 수집할 수 있는데. 그런데, 이 데이터 셋을 실제로 수집하려면 많은 노력이 필요하지만, 다행히도 이미 많은 우수한 품질의 데이터 셋이 준비되어 있습니다.
그런 다음 이 데이터 셋을 입수하면 우리는 이 기계학습 분류기를 학습시켜 모든 데이터를 수집하고, 어떤 방식으로 요약한 다음, 이런 다양한 개체 범주를 인식하는 방법에 대한 지식을 요약한 모델을 제시합니다. 마지막으로, 우리는 이 훈련 모델을 사용하여 새로운 이미지에서 고양이와 개 등을 인식할 수 있도록 적용할 것입니다.
따라서 여기 우리의 API가 조금 바뀌었는데. 하나의 이미지를 입력만 하고 고양이를 인식하는 단일 함수보다는 이 두 가지 함수가 있습니다. 하나는 학습(train)이라고 불리는 것으로, 이미지와 레이블을 입력받아 모델을 출력하는 것이다. 그리고 다른 함수는 예측(predict)라고 불리며, 이것은 모델을 입력하고 이미지에 대한 예측을 하는 것입니다.
그리고 이것은 이 모든 것들이 지난 10년, 20년 동안 정말 잘 작동하기 시작하도록 해 준 핵심 통찰력입니다.
따라서 이 수업은 주로 신경망(Neural networks), CNN(Convolutional neural networks), 딥러닝(Deep learning)에 관한 것입니다. 하지만 데이터 기반 접근방식(Data-driven approach)은 단순히 딥러닝이라기보다는 훨씬 더 보편적입니다.
그리고 우리가 크고 복잡한 분류자(classifier)를 하기 전에, 아주 간단한 분류자를 통해서 이 과정을 한 걸음씩 나아가는 것이 유용하다고 생각합니다.
First Classifier : Nearest Neighbor

그래서 아마도, 여러분이 상상할 수 있는 가장 간단한 분류자는 우리가 최근접 이웃(Nearest neighbor)이라고 부르는 것입니다. 솔직히는 그 알고리즘은 정말 바보 같긴한데. 학습 단계에서는 아무것도 하지 않을 것이고, 그저 모든 훈련 데이터를 외우는 것입니다.
이것은 매우 간단한데. 예측 단계에서, 새로운 이미지를 가지고 교육 데이터에서 새로운 이미지와 가장 유사한 이미지를 찾아내고, 가장 유사한 이미지의 레이블을 예측 하는 것입니다. 아주 간단한 알고리즘이지만 데이터 기반성(data-drivenness)이나 그 무엇과도 관련하여 많은 훌륭한 특성들을 가지고 있습니다.
Example Dataset : CIFAR-10

좀 더 구체적으로 말하자면, 기계 학습에 매우 흔히 사용되는, 일종의 작은 테스트 케이스인 CIFAR-10이라는 데이터셋을 작업하는 것을 상상해 봅시다. 그리고 여러분은 이 데이터셋을 숙제에 사용하게 될 것입니다.
CIFAR-10 데이터셋은 10가지 클래스를 제공하는데, 비행기, 자동차, 새, 고양이 등 다양한 클래스를 제공합니다. 그리고 각 10개 카테고리에 대해 대략적으로 50,000개의 교육 이미지를 제공합니다. 그리고 알고리즘을 테스트하기 위한 10,000개의 추가적인 테스팅 이미지가 있습니다.
다음은 CIFAR-10의 일부 테스트 이미지에 최근접 이웃 분류기를 적용하는 예시입니다. 우측 그리드에서 가장 왼쪽 열에 대한 테스트 이미지를 CIFA-10 데이터셋에 제공하고 오른쪽은 교육 이미지를 분류하고 각 테스트 예제와 가장 유사한 교육 이미지를 보여줍니다.
비록 항상 정확하지는 않지만 여러분은 이것들이 훈련 이미지와 시각적으로 비슷해 보이는 것을 볼 수 있는데, 두 번째 줄에서는, 테스트가 좀 어렵다는 것을 알 수 있는데 왜냐하면 이 이미지들은 32 x 32 픽셀이기 때문입니다. 두 번째 줄의 이 이미지는 개이고 가장 가까운 이웃도 개이지만 다음 사진들은 사실 사슴이나 말 같은 것들입니다.
하지만, 보다시피 꽤 비슷하게 생겼는데, 중간에 하얀 얼룩 같은 것이 있기 때문일 것입니다. 이 이미지에 최근접 이웃 알고리즘을 적용하면 훈련 데이터셋에서 가장 가까운 예를 찾을 수 있으며 가장 가까운 예제의 레이블을 알고 있는데. 왜냐하면 그것은 훈련 데이터셋으로부터 왔기 때문입니다. 간단히 말해서 우리는 이 테스트 이미지도 개라고 할 수 있으며 이 예시들을 보면 아마 잘 되지 않는다는 것을 알겠지만, 그래도 이 예시가 작업을 하기에는 여전히 좋은 예시라는 것입니다.
하지만 우리가 알아야 할 한 가지 세부 사항은, 한 쌍의 이미지를 볼 때, "우리가 어떻게 그것들을 실제로 비교할 수 있을까?" 하는 것입니다. 왜냐하면, 만약 우리가 테스트 이미지를 가지고 모든 학습 이미지와 비교한다면, 우리는 실제로 그 비교 함수가 어떻게 보여야 하는지에 대해 다양한 선택을 할 수 있기 때문입니다.
Distance Metric to compare images

그 전 슬라이드의 예시에서, 우리가 L1 거리(L1 Distance) 또는 맨해튼 거리(Manhattan Distance)라고 불리는 것을 사용했습니다. 이것은 이미지를 비교하기 위한 정말 간단하고 쉬운 아이디어인데, 이것이 바로 우리가 이 이미지들의 개별 픽셀들을 비교하는 겁니다.
맨해튼 거리(Manhattan Distance) 측정법은 인공지능에서 자주 나오며, Taxicab distance, rectlinear distance, city block distance, L1 distance와 같은 여러 별명을 가지고 있다.
그래서 우리의 테스트 이미지가 4 by 4 픽셀 값의 아주 작은 이미지라고 가정할 때, 우리는 테스트 이미지(test image)의 왼쪽 상단 픽셀을 가져가고, 훈련 이미지(training image)의 값을 빼내고, 절댓값을 취하여서, 두 이미지 사이의 픽셀 차를 얻습니다. 그리고 이 모든 것을 이미지의 모든 픽셀에 걸쳐 합합니다.
이것은 이미지를 비교하는바보 같은 방법이지만, 때때로 합리적이기도 합니다. 하지만, 이것은 우리에게 두 이미지 사이의 차이를 측정하는 매우 구체적인 방법을 제공하는데. 이 경우, 이 두 이미지 사이에는 456개의 차이가 있다는 것입니다.
import numpy as np
class NearestNeighbor:
def _init_(self):
pass
def train(self, X, y):
"""X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i'th test imgae
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred여기 최근접 이웃 분류자를 구현하기 위한 완전한 Python 코드가 있는데, NumPy가 제공하는 많은 벡터화 작업을 사용했기 때문에 꽤 짧고 간결합니다. 우리가 앞서 이야기한 이 훈련 함수는 다시 한번 말 하지만 아주 간단합니다. 최근접 이웃의 경우에는 단지 훈련 데이터를 외우기만 하면 되기에 별로 할 일이 없습니다.
그리고 테스트 시점(test time)에 이미지를 가지고 L1 거리 함수(L1 distance function)를 사용하여 비교합니다. 테스트 이미지는 각각의 훈련 예제와 비교되고, 가장 유사한 예를 훈련 세트에서 찾을 것입니다.
보다시피, 우리는 NumPy에서 벡터화된 작업을 이용하여 Python 코드 한두 줄만으로 이 작업을 수행할 수 있기에 따라서 이것을 여러분들이 첫 과제에서 연습하게 될 겁니다.

자, 이제, 이 간단한 분류자에 대한 몇 가지 문제가 있는데. 먼저, 교육용 데이터셋에 N개의 예가 있다면, “교육 및 테스트의 속도가 얼마나 빠를 것으로 예상할 수 있을까?” 하는 것입니다.
학습은 아마도 일정할 겁니다. 왜냐하면 우리는 아무것도 할 필요가 없기 때문인데 우리는 단지 데이터를 외우기만 하면 됩니다. 만약 우리가 포인터를 복사하는 경우 데이터셋의 크기가 아무리 커도 일정한 시간이 걸리게 됩니다.
하지만 이제 테스트 시점(test time)의 이러한 비교는 중단하고 데이터셋의 각 N 훈련 예제와 테스트 이미지를 비교해야 하는데 사실 이것은 꽤나 느립니다. 생각해보면, 이것은 사실 다소 거꾸로 된 것인데, 왜냐하면, 실제로, 우리는 우리의 분류기들이 학습 시점에는 느리고, 테스트 시점에는 빠르기를 원하기 때문입니다. 왜냐하면, 여러분이 상상할 수 있듯, 분류자는 데이터 센터에서 훈련 받을 수 있고, 여러분은 분류자를 정말 잘 만들기 위해 테스트 시점에 많은 계산을 할 수 있도록 할 수 있는 여유가 있기 때문입니다.
하지만, 테스트 시점에 분류기를 배포하고 나서 휴대전화의 브라우저 또는 기타 저전력 장치에서 실행하는 데 있어서 분류기의 테스트 시간 성능을 상당히 빠르게 유지하길 원한다면 이 관점에서, 최근접 이웃 알고리즘은 실제로 조금 뒤떨어집니다. 그리고 CNN과 다른 유형의 파라메트릭 모델(Parametric model)로 간다면, 반대가 될 것입니다. 학습 시점(training time)에 많은 계산을 소비하게 될 것이지만, 테스트 시간(test time)은 꽤 빠를 것입니다.
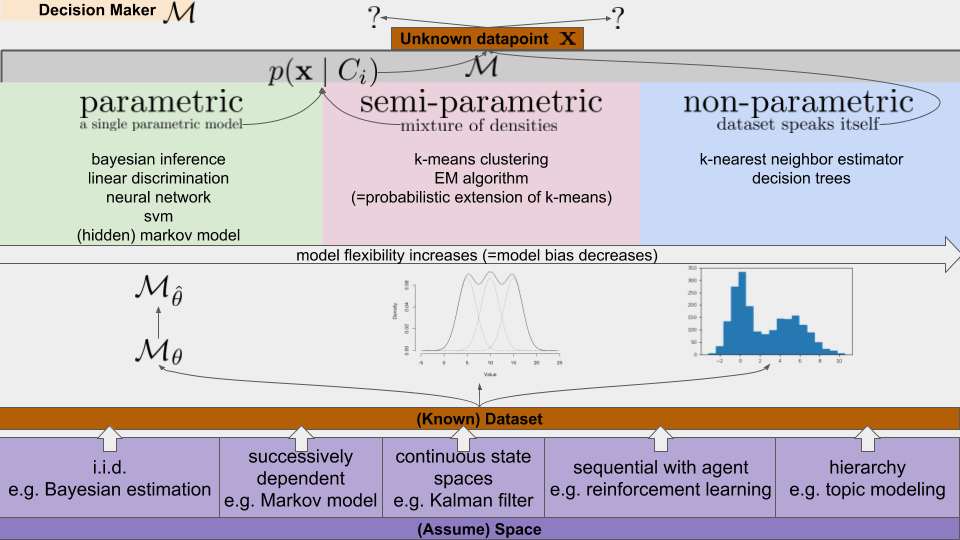
머신러닝 모델은 모델의 구조에 따라 크게 세 가지로 분류할 수 있다. 1. parametric 모델, 2. Semi-parametric 모델, 3. Non-parametric 모델
1. parametric model: 사람이 적합한 구조의 모델을 선택한 후에, 데이터셋을 집어넣어서 그 모델에 들어있는 파라미터(parameter)를 튜닝하는 방식으로 학습을 한다. 그래서 찾아낸 최적의 파라미터는 theta 위에 세모 모자를 씌워놓은 변수로 표시한다. 그래서 본 적 없는 데이터 (unknown datapoints) x를 어느 곳으로 보내야 할지 확률적으로 p(x|C) 결정을 한다.
2. semi-parametric model : 여러 모양의 국소적인 (local) 확률 밀도 (density)를 중첩해서 통합된 확률 밀도 함수를 구하며, non-parametric과 parametric 모델의 중간 형태라고 볼 수 있다.
3. Non-parametric model : 파라미터를 추정하거나 교정하는 식으로 동작하지 않는다. 데이터가 스스로 말하게 하는 것인데(dataset speaks itself) 단순하게 보면 히스토그램을 사용한다고 말할 수 있다. 데이터의 분포를 표현해놓고, 비슷한 입력에는 비슷한 출력을 내놓는다는 방침만 세우는 것.
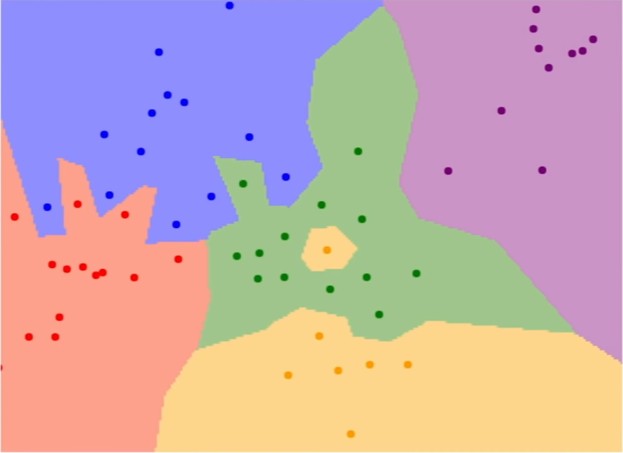
그래서 문제는 “정확히 최근접 이웃 알고리즘을 실제로 적용할 때에 어떻게 보이는가?”입니다. 그래서 여기에 최근접 이웃 분류자의 결정 영역이라고 부르는 것을 그려보았습니다. 여기에서 우리의 훈련 세트(training set)는 2차원 평면에서 이 점들로 구성되며 여기서 점의 색은 해당 점의 범주 또는 클래스 레이블을 나타냅니다.
여기 5 개의 클래스가 있고, 파란색 클래스가 위 모서리에 있고 오른쪽 상단 모서리에는 보라색 클래스가 있습니다. 이제 이 전체 평면의 각 픽셀에 대해 이 훈련 데이터(training data)에서 가장 가까운 예제가 무엇인지 계산하고, 그다음 클래스 레이블에 해당하는 점들의 배경을 해당하는 색으로 채웠습니다.
따라서, 이 최근접 이웃 분류자는 공간을 조각하고 근처의 포인트에 따라 공간을 채색하는 것과 같지만 이 분류 기준은 그렇게 좋지 않을 수도 있습니다. 그리고 이 그림을 보면 가장 최근접 이웃 분류자로 나올 수 있는 몇 가지 문제를 볼 수 있는데.
첫 번째로, 이 중앙 지역은 실제로 대부분 녹색 지점을 포함하지만 중간에 작은 노란색 지점이 하나 있습니다. 그러나 최근접 이웃을 보고 있기 때문에, 녹색 클러스터의 중간에 작은 노란색 섬이 나타나게 됩니다. 아마 이것은 그렇게 좋지는 않을 것인데. 어쩌면 그 점들은 실제로 녹색이었을 수도 있으며, 비슷하게 녹색 영역이 일종의 손가락으로 밀어 넣는 것처럼 파란색 영역을 밀어 넣는 것을 볼 수 있는데. 다시 말해 마찬가지로 점들의 존재 여부로 인해서 noisy 하거나 거짓될(spurious) 수도 있습니다.

따라서, 이런 종류의 알고리즘은 K-최근접 이웃(K-nearest neighbors)이라고 불리는 알고리즘의 약간의 일반화를 유발하며 가장 가까운 하나의 이웃을 찾는 것보다, 조금 더 팬시(fancy)한 것을 하면서 최근접 이웃의 K를 찾은 다음 거리 측정 기준에 따라 이웃들에게 투표를 합니다. 그리고 이웃 사이에서 다수의 표를 예측(predict)합니다.
이 작업을 조금 더 복잡한 방법으로 생각할 수 있는데, 어쩌면 거리에 가중치를 붙이는 등의 투표를 할 수도 있지만, 가장 잘 작동하는 가장 간단한 방법은 과반수 득표만 하는 겁니다. 그래서 여기에서 우리는이 K = 1 최근접 이웃 분류자를 사용하여 정확하게 동일한 세트를 보여 주었고 중간과 오른쪽에서 K = 3과 K = 5를 사용했습니다.
일단 K = 3으로 가보면, 녹색 클러스터의 중간에 있는 가짜 노란색 점이 더 이상 해당 지역 근처의 점을 노란색으로 분류하지 않음을 알 수 있는데, 이제 중간에 있는 전체 녹색 부분이 모두 녹색으로 분류되며, 빨간색과 파란색 지역의 손가락이 이 다수결로 인해 매끈해지기 시작했음도 알 수 있습니다. 그러고 나서 K = 5로 가보면 파란색과 빨간색 영역 사이의 결정 경계(decision boundaries)가 꽤 부드럽고 괜찮아 진걸 볼 수 있습니다.
따라서 일반적으로 최근접 이웃 분류 기준을 사용할 때 거의 항상 K의 값을 사용하고자 하는데. 이 값은 결정 경계를 다듬어 더 나은 결과를 유도하기 때문에 1보다 큽니다.
Question : What is the deal with these white regions?
학생의 질문은 "저 흰색 영역은 무엇인가?" 하는 것인데. 흰색 영역은 K-최근접 이웃 사이에서 다수(majorirty)가 없는 영역입니다. 아마도 약간 더 팬시한 것을 하고, 아마 추측하거나 무작위로 다수의 승자(majority winner) 중에서 선택하는 것을 상상할 수 있는데, 그러나 이 예제에서는 그 점에 최근접 이웃이 없다는 것을 나타내기 위해 흰색으로 채색하였습니다.
우리가 컴퓨터 비전에 대해 생각할 때마다, 여러 가지 관점 사이에서 앞뒤로 뒤집는 것이 정말 유용하다고 생각합니다. 하나는 평면에서 고차원적 시점에 대한 아이디어이며, 다른 하나는 실제로 구체화된 이미지를 보는 겁니다. 왜냐하면 이미지의 픽셀은 실제로 우리가 이러한 이미지를 고차원적인 벡터로 생각할 수 있게 해 주기 때문이며, 그리고이 두 가지 다른 관점 사이에서 앞뒤로 주고받는 것이 유용하기 때문입니다.
What does this look like?

다음으로, 이 K-최근접 이웃을 가져다가 이미지로 돌아가는 것은 실제로 좋지 않다는 것을 알 수 있는데, 여기서 나는 이미지가 실제로 최근접 이웃에 따라 정확하게 또는 틀리게 분류(classified correctyl or incorrectly) 된 것을 빨강과 초록으로 색칠하는데, 이것이 정말로 좋지 않다는 것을 알 수 있습니다.
하지만 아마 우리가 더 큰 값의 K를 사용했다면 아마 이것은 상위 3 개 또는 상위 5 개 또는 어쩌면 전체 행 중에서 투표하는 것을 포함했을 것입니다. 그리고 여러분은 이런 식으로 이웃을 찾을 때 보이는 이런 소음의 일부에도 훨씬 더 강해질 것이라고 상상해볼 수 있습니다.
K-Nearest Neighbors : Distance Metric

그래서 우리가 K- 최근접 이웃 알고리즘으로 작업할 때 가지고 있는 또 다른 선택지는 우리가 어떤 식으로 다른 점들을 정확하게 비교하는지를 결정하는 겁니다. 예를 들어 지금까지는 픽셀 사이의 절대 값의 합을 사용하는 L1 거리(L1 distance)에 대해 이야기했지만, 또 다른 일반적인 선택지는 사각형의 합을 제곱하고 이것을 거리(distance)로 사용하는 L2 또는 유클리드 거리(euclidean distance)입니다.
서로 다른 거리 메트릭스(distance metrics)를 선택하는 것은 실제로 흥미로운 주제입니다. 왜냐하면 서로 다른 거리 메트릭스가 공간에서 기대할 수 있는 근본적인 기하(geometry) 또는 위상(topology)에 대해 서로 다른 가정을 하기 때문입니다. 따라서, 이 L1 거리는 L1 거리에 따라 실제로 원(circle)이고 이 원점(origin) 주위에 사각형 모양을 형성하는데, 정사각형 상의 각 점이 L1에 따라 원점에서 등거리(equidistant)에 있는 반면 L2 또는 유클리드 거리에서의 원은 우리가 생각하는 친숙한 원인 것입니다.
특히 이 두 메트릭스 지표(two metrics particular) 사이에서 지적해야 할 한 가지 흥미로운 점은 L1 거리는 사용자가 선택한 좌표 시스템에 따라 달라진다는 것입니다. 따라서 만약 우리가 좌표계를 회전시키면 실제로 점 사이의 L1 거리를 변경하게 되는 것인데. 반면에 L2 거리에서 좌표 프레임을 변경하는 것은 별로 중요하지 않으며, 우리가 사용하는 좌표 프레임이 무엇이든지 상관없이 같기도 합니다.
만약 우리의 입력 피처(input features)에서, 벡터 안의 개별 항목들이 우리 작업에 중요한 의미를 갖는다면, 어쩌면 L1이 적합할 수도 있습니다. 하지만 만약 그것이 어떤 공간의 일반적인 벡터일 뿐이며 어떤 다른 요소들 중 어떤 것이 실제로 무엇을 의미하는지 모른다면, 아마도 L2가 조금 더 자연스러울 겁니다.
그리고 여기서 또 다른 요점은 다른 거리 메트릭스를 사용함으로써 우리는 실제로 벡터와 이미지뿐만 아니라 정말 많은 다른 유형의 데이터로 K-최근접 이웃 분류기를 일반화할 수 있다는 것입니다. 예를 들어, 우리가 텍스트 조각을 분류하기를 원한다고 상상해봅시다. 그러면 우리가 이 K-최근접 이웃을 사용하기 위해 할 수 있는 유일한 것은 아마도 두 개의 단락이나 두 개의 문장과 같은 것들 사이의 거리를 측정할 수 있는 거리 함수(distance function)를 지정하는 것입니다.
따라서 단순히 다른 거리 측정지표를 지정함으로써 이 알고리즘을 기본적으로 모든 유형의 데이터에 일반적으로 적용할 수 있습니다. 비록 단순한 알고리즘이지만, 일반적으로 새로운 문제를 볼 때, 먼저 시도해 보는 것도 좋은 방법이며, 우리가 다른 거리 측정기를 선택한다면, 실제로 어떤 일이 일어날지 생각해 보는 것도 흥미로운 이야기 입니다.

여기 왼쪽에서 L1 혹은 맨해튼 거리를 사용하고 오른쪽에서 친숙한 L2 또는 유클리드 거리를 사용하는 동일한 점 집합을 볼 수 있습니다. 그리고 이러한 결정 경계(decision boundaries)의 형태가 실제로 두 지표 사이에서 상당히 많이 변화하고 있음을 알 수 있습니다.
우리가 L1을 보면, 이 결정 경계는 좌표축을 따르는 경향이 있는데. 다시 한번 말하면 이것은 L1이 우리의 좌표계(coordinate system) 선택에 달려있기 때문입니다. L2는 좌표축(coordicate axis)을 별로 신경 쓰지를 않으며, 자연스럽게 떨어질 수 있는 경계(boundaries)를 놓기만 합니다.
K-Nearest Neighbors : Demo Time

http://vision.stanford.edu/teaching/cs231n-demos/knn/
제가 고백하건대, 제가 여러분께 보여드린 각각의 사례들은 실제로 제가 만든 이 상호작용적인 웹 데모에서 나온 것입니다. 여러분이 직접 가서 이 K-최근접 이웃 분류기와 함께 놀 수 있는 곳이지요. 그리고 이것은 프로젝터 화면에서 작업하기 정말 어렵기 때문에. 아마 각자 해보면 될 것 같습니다. 자, 다시 주제로 돌아와서.... 이런 좀 창피한 일이긴 한데, 별거 아닌데 문제가 나서 작동이 안 되니... 이 이야기는 생략하고 여러분들의 브라우저에서 각자 실행해보기를 권장하겠습니다.
사실 K와 거리 메트릭스(distance metrics)를 바꿔가면서 결정 경계(decision boundary)가 어떻게 변하는지 직관(intuition)을 만드는 것은 꽤 재미있고 좋은 일입니다. 그렇다면 여기서 문제는 일단 여러분이 실제로 연습을 위해 이 알고리즘을 사용하려고 하면, 여러분이 선택해야 할 몇 가지 선택이 있다는 것인데 우리는 K의 다른 가치를 선택하는 것과, 다른 거리 메트릭스(distance metrics)를 선택하는 것에 대해 이야기했습니다. 문제는 우리의 데이터를 위해서 어떻게 이런 선택을 하느냐 하는 겁니다.
그래서 K나 거리 메트릭스와 같은 이러한 선택들을 우리는 하이퍼 파라미터(hyperparameters)라고 부르는데, 왜냐하면 그것들은 훈련 데이터로부터 반드시 학습되는 것이 아니기 때문이고, 대신 이것들은 여러분이 미리 만들어 놓은 알고리즘에 대한 선택이고, 데이터로부터 직접 그것들을 배울 수 있는 방법이 없기 때문입니다.
그렇다면, 문제는 어떻게 이런 것들을 실행(practice) 하냐는 겁니다. 그리고 그것들은 매우 문제-의존적인(problem-dependent) 것으로 판명되는데. 대부분의 사람들이 간단히 하는 일은, 단순히 여러분들의 데이터와 문제를 위해 하이퍼 파라미터의 어떤 값이 가장 잘 작동하는지 시도해보는 것입니다.
Question: Where L1 distance might be preferable to using L2 distance?
학생의 질문은 “L2 distance 보다 L1 distance를 사용하기 더 좋을 수 있는 곳이 있느냐?”인데, 나는 그것이 주로 문제 의존적(problem-dependent)이라서, 어떤 경우에 어떤 것이 다른 것보다 더 낫다고 생각하는지를 말하기는 다소 어렵다고 생각을 합니다. 하지만 L1이 이런 종류의 좌표 의존성(cooridinate dependency)을 가지고 있기 때문에, 사실 당신이 벡터를 가지고 있다는 것을 안다면, 그것은 실제로 여러분의 데이터의 좌표계(coordinate system)에 달려있다고 생각합니다. 그리고 아마도 벡터의 각각의 요소들은 의미를 가지고 있을 것입니다. 예를 들어서 어떤 이유로 직원들을 분류하는 것처럼, 그 벡터의 여러 요소들은 직원의 다양한 특징이나 측면에 해당할 수 있는데. 직원들의 봉급이나 회사에서 일한 년수 같은 것처럼 말입니다.
그래서 각각의 요소들이 실제로 어떤 의미를 가지고 있을 때, 아마도 L1을 사용하는 것이 조금 더 말이 될 것 같지만, 일반적으로, 다시 말하지만, 이것은 하이퍼 파라미터(hyperparameter)이며 그리고 그것은 정말로 문제와 데이터에 달려있기 때문에 가장 좋은 답은 둘 다 시도해보고 무엇이 더 잘 작동하는지 보는 것이라고 생각합니다.

하이퍼 파라미터의 다양한 값을 시도해보고 무엇이 가장 잘 작동하는지를 보는 이 아이디어 조차도, 많은 다양한 선택들이 있는데. “하이퍼 파라미터를 사용해보고 무엇이 가장 잘 작동하는지 보는 것이 정확히는 무엇을 의미하는가?”에 대해서 생각해보면, 여러분이 생각할 수 있는 첫 번째 아이디어는 단순히 훈련 데이터에 대한 최고의 정확성 또는 최고의 성능을 제공하는 하이퍼 파라미터들을 선택하는 것입니다. 이것은 사실 정말 끔찍한 생각이며 절대로 이러면 안 됩니다.
구체적인(concrete) 최근접 이웃 분류자의 경우에, 예를 들어 K=1로 설정하면, 훈련 데이터를 항상 완벽하게 분류할 것입니다. 따라서 이 전략을 사용하면 항상 K=1을 선택할 수 있지만, 앞서 예에서 보듯이 실제로 K를 더 큰 값으로 설정하면 일부 훈련 데이터를 잘못 분류할 수 있지만, 실제로는 훈련 데이터에 없는 지점에서 더 나은 성능을 얻을 수 있습니다. 그리고 궁극적으로 기계 학습에서는 훈련 데이터를 적합(fitting)시키는 것에는 그다지 신경 쓰지 않고, 훈련 후에 우리의 분류자, 또는 우리의 방법(method)이 모르는 데이터(unseen data)에 어떻게 작용할지를 정말로 신경 씁니다.

그러니, 이건 끔찍한 생각이므로 이러면 안 됩니다. 여러분이 생각하실 수 있는 또 다른 아이디어는 아마도 전체 데이터셋을 가지고 훈련 데이터와 테스트 데이터로 나누어 볼 수 있을 겁니다. 이제 나는 훈련 데이터에 대한 하이퍼 파라미터의 다양한 선택지로 알고리즘을 훈련시켜 보고, 그 훈련된 분류기를 시험 데이터에 적용하고, 이제 시험 데이터에 대해 가장 잘 수행하게 하는 하이퍼 파라미터 세트를 선택할 것입니다.
이것은 어쩌면 더 합리적인 전략처럼 보이지만, 사실 이것도 끔찍한 생각이고 절대 이렇게 해서는 안 됩니다. 왜냐하면, 다시 말하지만, 기계학습 시스템의 핵심은 알고리즘이 어떻게 작동하는지를 알고 싶다는 것입니다. 테스트 세트의 요점은 손대지 않은(wild) 데이터에서 나온 모르는 데이터(unseen data)에 대해 우리의 방법이 어떻게 작용할지 추정하는 것이며, 그리고 만약 우리가 다양한 하이퍼 파라미터로 많은 다양한 알고리즘을 훈련시키는 전략을 사용한다면, 그리고 테스트 데이터에서 가장 잘 작동하는 알고리즘을 선택한다면, 우리가 알고리즘을 이 테스트 세트에서 잘 작동하게 만든 적절한 하이퍼 파라미터 세트를 선택했을 가능성이 있지만, 이제 이 테스트 세트에서 우리의 성능은 더 이상 새 로고 모르는 데이터(unseen data) 성능을 대표하지 않을 것입니다. 그러니 다시 말하지만, 이렇게 해서는 안 된며, 이건 좋지 않은 생각이고, 이렇게 하면 큰일 납니다.

훨씬 더 흔한 방법은 실제로 여러분의 데이터를 세 개의 다른 세트로 나누는 것입니다. 대부분의 데이터를 학습 세트(training set)로 분할한 다음 검증 세트(validation set)와 테스트 세트(test set)를 생성합니다. 이제 우리가 일반적으로 하는 일은 훈련 세트에 있는 많고 다양한 하이퍼 파라미터로 알고리즘을 훈련시키고, 검증 세트에서 평가하고, 검증 세트에서 가장 잘 동작하는 하이퍼 파라미터 세트를 선택하는 겁니다.
그리고 이제, 모든 개발과 디버깅 끝낸 후에, 여러분은 검증 세트(validation set)에서 가장 성능이 좋은 분류기(classifier)를 가져다가 테스트 세트(test set)에서 한 번 실행하게 될 겁니다. 그리고 이 숫자는 곧, 여러분의 논문에 들어가는 숫자이며, 여러분의 보고서에 들어가는 숫자이고, 여러분의 알고리즘이 모르는 데이터(unseen data)에서 어떻게 작동하고 있는지를 실제로 알려주는 숫자입니다.
그리고 검증 데이터(validation data)와 테스트 데이터(test data)를 엄격하게 분리 유지하는 것이 매우 중요한데. 예를 들어, 우리가 연구 논문 작업을 할 때에, 보통 마지막 순간에 테스트 세트를 만집니다. 그리고, 나는 논문을 쓰고 있을 때면 아마 마감일 일주일 전에 테스트 세트를 다루는 있기 때문에 따라서 여기서 우리가 비-정직하고, 불공평한 수를 쓰지 않는다는 것을 확실히 보증하며, 실제로 이것은 매우 중요하기에 여러분은 여러분의 테스트 데이터를 확실히 제어해야 합니다.

하이퍼 파라미터를 설정하는 또 다른 전략을 교차 검증(cross validation)라고 하는데. 이것은 작은 데이터 세트에 조금 더 일반적으로 사용되며 딥러닝(deep learning)에는 그다지 많이 사용되지는 않습니다. 이 아이디어는 우리의 테스트 데이터 혹은 데이터 세트를 가져다가, 마지막에 사용할 테스트 세트를 준비하고, 나머지 데이터에 대해서는, 단일 테스트 및 검증 파티션으로 분할하는 대신에 학습 데이터를 다양한 폴드(fold)로 분할하는 것입니다.
이제 이러한 방식으로 어떤 폴드가 검증 집합(validation set)이 될지 선택하는 과정을 반복하고. 이 예제에서 5개의 폴드 교차 검증(cross validation)을 사용하므로 처음 4 개의 폴드의 하나의 하이퍼 파라미터 세트로 알고리즘을 학습하고 폴드 4에서 성능을 평가 한 다음 폴드 1, ,2 3, 5에서 알고리즘을 재-학습시키고, 폴드 4에서 평가하고 이 과정을 모든 폴드들을 돌아가며 반복합니다.
이 방법을 사용하면 어떤 하이퍼 패러미터가 더 강력하게 수행되는지에 대해 높은 자신감을 갖게 될 텐데. 이것은 사용하기에 적합한 표준이 지긴 하지만 그러나 실제로 딥러닝을 사용하여 대형 모델을 학습할 때 계산에 자원이 많이 필요하여(computationally expensive), 실제로는 많이 사용되지는 않습니다.
Question :What’s difference between the training and the validation set?
질문은 “좀 더 구체적으로 학습 세트과 검증 세트의 차이점이 무엇인가?”하는 것인데. K-최근접 이웃 분류자를 생각해 보면 학습 세트는 우리가 암기해야 하는 레이블 이미지 세트입니다. 이미지를 분류하기 위해, 이미지를 학습 데이터의 각 요소와 비교 한 다음 최근접 학습 포인트(nearest training point)에서 레이블을 전송합니다. 이제 알고리즘은 학습 세트의 모든 것을 암기할 것이고, 검증 세트의 각 요소를 가져다 학습 데이터의 각 요소와 비교하고, 검증 세트에 적용되었을 때 분류자의 정확도를 결정하는데, 이것이 학습과 검증의 구분이다. 알고리즘이 학습 세트의 레이블을 볼 수 있지만 검증 세트의 경우 알고리즘은 레이블에 직접 접근할 수 없습니다. 따라서 검증 세트의 레이블은 오로지 알고리즘이 얼마나 잘 수행되고 있는지 확인하는 데 사용합니다.
Question : Where the test set, is it possible that the test set might not be representative of data out there in the wild?
질문은 “테스트 세트가 저 밖에 야생의(wild) 데이터를 대표하지 못할 가능성이 있는가?” 하는 것입니다. 이는 분명히 문제가 될 수 있으며, 여기서 기본적인 통계적 가정은 모든 데이터가 독립적이고 동일하게 분포되어 있기 때문에 모든 데이터 포인트가 동일한 기본 확률 분포에서 도출되어야 한다는 것입니다. 물론, 실제로, 항상 그렇지는 않을 수도 있고, 여러분은 테스트 세트가 야생에서 보는 것을 아주 대표하지 못할 수도 있는 경우에 직면할 수도 있는데.
이런 문제는 데이터 세트 작성자와 데이터 세트 큐레이터들이 생각해야 할 문제입니다. 하지만 데이터셋을 만들 때, 예를 들어, 한 가지 방법은, 데이터 수집을 위해 한 번에 많은 데이터를 수집하고 그러고 나서 무작위로 학습 데이터와 테스트 데이터를 분할하는 겁니다.
여기서 망칠 수 있는 한 가지는 아마도 여러분이 데이터를 수집하고 초기 데이터를 만들 때에 처음으로 학습 데이터를 만들고, 나중에 수집하는 데이터가 테스트 데이터가 된다면, 문제를 일으킬 수 있는 변화에 직면하게 될지도 모른다는 겁니다. 그러나 이 파티션이 전체 데이터 포인트 세트에서 무작위로 이루어지는 한, 이것이 이 문제를 완화하기 위해 노력하는 방법입니다.
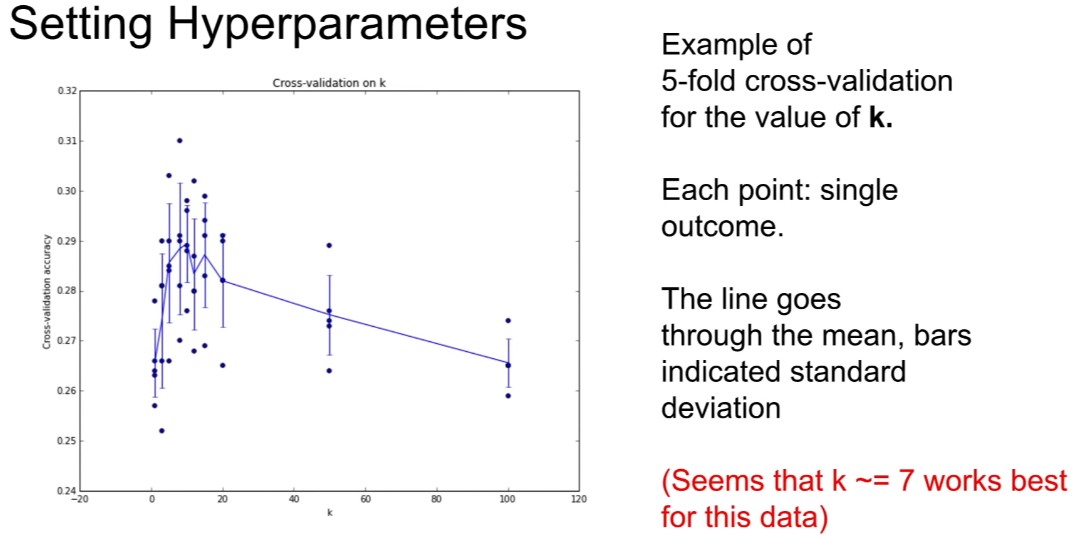
그러면 일단 이 교차 검증 절차를 거치고 나면 결국 이와 유사한 그래프로 끝나게 된다. 여기서 X축에서는 어떤 문제에 대한 k-최근접 이웃 분류기에 대한 K의 값을 보여주고 있으며, 지금 Y축에서는 K의 다른 값에 대한 어떤 데이터 세트에서 우리의 분류기의 정확도가 얼마인지를 보여주고 있습니다.
보다시피, 이 경우에는 데이터에서 5개의 교차 검증을 수행했고, K의 각 값에 대해 이 알고리즘이 얼마나 잘 작동하는지 보여주는 5가지 다른 예시가 있는데, 실제로, 알고리즘에 더 좋거나 더 나쁜 테스트 세트가 있다는 질문으로 돌아가 보면, K폴드 교차 검증을 사용하는 것이 아마도 이것을 정량화하는 데 도움이 되는 한 가지 방법 중 하나일 겁니다. 그리고, 그 안에서, 우리는 이 알고리즘이 다른 검증 폴드(validation folds)에서 어떻게 수행되는지에 대한 차이를 볼 수 있을 것입니다.
그러고 이것은 여러분에게 무엇이 최고인지 뿐 아니라, 그 성능에 기여하는 것이 무엇인지에 대한 감각을 줍니다. 따라서 기계학습 모델을 훈련시킬 때마다 이런 플롯(plots)을 만들게 되는데, 이 플롯은 정확도가 얼마인지, 하이퍼 파리미터의 함수로서 성능을 보여주고, 그러고 나서 검증 세트에서 최고의 성능을 발휘하는 모델, 즉 하이퍼 파라미터 세트를 고르길 원하게 되는 것입니다. 그리고 여기서는 아마 K=7이 이 문제에서 가장 최선일 것이라고 보는 겁니다.

따라서 이미지 상의 K-최근접 이웃 분류기들은 실제로 거의 사용하지 않습니다. 왜냐하면, 우리가 얘기했던 이 모든 문제들과 함께. 한 가지 문제는 테스트 시간이 굉장히 느리다는 것인데, 앞서 이야기했던 것처럼 우리가 원하는 것과 반대로 하는 겁니다.
또 다른 문제는 유클리드 거리 혹은 L1 거리와 같은 것들이 이미지들 사이의 거리를 측정하는 아주 좋은 방법이 아니라는 것입니다. 이러한 벡터 거리 함수는 이미지 간의 지각적 유사성(perceptual similarity)과 매우 잘 일치하지 않습니다.
이미지 간의 차이를 인식하는 방법은 이 예에서 우리는 왼쪽에 소녀 이미지가 있고, 오른쪽에는 입을 막는 등 세 개의 다른 왜곡된 이미지가 있는데 실제로 몇 픽셀씩 아래로 움직이거나, 아니면 전체 이미지를 파란색으로 색칠한 것입니다. 그리고, 실제로, 원본과 왜곡된 이미지들의 거리를 계산해 보면, 모두 L2 거리가 같다. 이는 L2 거리가 이미지 사이의 인식 거리를 포착하는 데 별로 도움이 되지 않는다는 느낌을 주기 때문에 그리 좋지 않을 수도 있습니다.

K-최근접 이웃 분류자의 또 다른 문제는 우리가 차원의 저주(curse of dimensionality)라고 부르는 것과 관련이 있는데. 우리가 가지고 있던 최근접 이웃 분류기의 관점을 다시 생각해보면, 그것은 각각의 훈련 데이터 지점 주위에 페인트를 떨어뜨려 공간을 분할하는 것인데. 즉, 만약 우리가 K-최근접 이웃 분류기가 잘 작동하기를 기대한다면, 우리는 공간을 꽤 촘촘하게 덮을 수 있는 훈련 예제(training examples)가 필요로 합니다.
그렇지 않으면 최근접 이웃이 우리의 테스트 포인트와 비슷하지 않거나 떨어져 있을 수도 있다는 것인데. 문제는 공간을 실제로 촘촘히 덮고 있다는 것은 차원 문제에 있어서 기하급수적인 여러 가지 훈련 예제가 필요하다는 것입니다. 이것은 매우 좋지 않은데, 기하급수적인 성장은 항상 좋지 않지만, 기본적으로 높은 차원 공간에서 픽셀의 공간을 조밀하게 덮을 수 있는 충분한 이미지를 얻을 수는 없기 때문입니다.

따라서 그것은 아마도 K-최근접 이웃을 사용할 때 명심해야 할 또 다른 하나일 것입니다. 요약하자면, 우리는 이미지 분류에 대한 아이디어를 소개하기 위해 K-최근접 이웃을 사용하고 있다는 것인데. 학습 세트의 이미지와 레이블을 가지고, 테스트 세트에 있는 레이블을 예측하기 위해 사용하는 겁니다.
Question : What was going on with this picture? What are the green and the blue dots?
질문은 “이 사진은 어떻게 된 것이고, 녹색과 파란 점은 무엇인가?” 인데. 여기, 포인트로 표현되는 학습 샘플들이 있는데, 점의 색상은 아마도 이 훈련 샘플의 포인트 범주를 나타내는 것입니다. 따라서 우리가 한 차원이라면, 4개의 훈련 샘플만 있으면 공간을 조밀하게 커버할 수 있지만, 우리가 2차원으로 이동한다면, 이제 4 * 4 = 16개의 훈련 예제들이 공간을 채우기 조밀하게 채우기 위해 필요로 한다는 것입니다.
그리고 3차원, 4차원, 5차원으로, 더 많은 차원으로 이동하면, 공간을 조밀하게 커버하기 위해 필요한 학습 예시의 수는 차원에 따라 기하급수적으로 증가합니다. 아마도 2차원에서 우리는 이런 종류의 재미있는 곡선을 가지고 있을 수도 있고, 다른 차원 공간에서 임의의 매니폴드(arbitrary manifolds) 레이블을 가지고 있을 수도 있을 것이다. K-최근접 이웃 알고리즘은 이러한 기초적인 매니폴드에 대해 실제로 어떠한 가정도 하지 않기 때문에, 제대로 수행할 수 있는 유일한 방법은 함께 작업해야 할 학습 포인트의 꽤 밀집된 샘플을 가지고 있는 경우뿐입니다.
따라서 이것은 K-최근접 이웃의 개요입니다. 여러분은 이것을 첫 번째 과제에서 실제로 구현하고 이미지로 시험해 볼 수 있는 기회를 얻게 될 것입니다. 그리고 K와 N에 대해서 질문이 없다면 다음 주제로 넘어가겠습니다.
Question : Why do these images have the same L2 distance?
질문은 “왜 이 이미지들이 같은 L2 거리를 가지고 있는가?”인데

그것에 대한 답은, L2 거리가 같도록 세심하게 설계했다는 겁니다. 하지만 단지 L2 거리가 이미지들 사이의 유사성을 측정하는 아주 좋은 척도가 아니라는 느낌을 줄 뿐인데. 그리고 이 이미지들은 사실 다른 방식으로 서로 다릅니다. K와 N을 사용하는 경우 이미지 사이의 거리를 측정해야 하는 유일한 방법은 이 단일 거리 메트릭스(single distance metric)인데. 따라서 이런 종류의 예는 거리 메트릭스가 실제로 이미지 사이의 거리 또는 차이에 대한 전체 설명(full description)을 캡처(capturing) 하지 못한다는 예를 보여 줍니다. 그래서 이 경우, translations과 offsets을 정확히 일치시키기 위해 조심스럽게 만들었습니다.
Question : Maybe this is actually good, because all of these things are actually having the same distance to the image.
질문은 “어쩌면 이 모든 것들이 실제로 이미지와 같은 거리를 가지고 있기 때문에, 그래서 좋은 것일지도 모른다”는 것인데. 이 예에서는 그럴지도 모르지만, 내 생각에는 우리가 두 개의 원본 이미지를 가지고 있는 예를 만들어서 상자를 적절한 장소에 놓거나 색칠함으로써, 우리는 여러분이 원하는 것에 더 가까이 가게 할 수 있을 겁니다. 왜냐하면 이 예에서 우리는 이 이미지들의 지각적 본질을(preceptional nature of these images) 바꾸지 않고도 이 거리들을 거의 임의적으로 변화시키기(arbitrary shifting) 위해 임의적인 이동과 색칠을 할 수 있기 때문입니다. 그래서, 만약 여러분이 다른 원본 이미지들을 많이 가지고 있다면, 이것은 여러분을 망칠 수 있다고 생각합니다.
Question : Whether or not it’s common in real-world casses to go back and retrain the entire dataset once you’ve found those best hyperparameters?
질문은 “실제 사례에서 최고의 하이퍼 파라미터가 발견되면 전체 데이터셋을 다시 테스트하는 것이 일반적인지? 여부”인데, 사람들은 때때로 이것을 실천에 옮기지만, 그것은 어느 정도 취향의 문제입니다. 만약 여러분이 정말로 마감일을 서두르고 있고, 정말로 이 모델을 꺼내야 한다면, 또 만약 당신이 전체 데이터셋에서 모델을 재교육하는데 오랜 시간이 걸린다면, 여러분은 아마 하지 않을 것입니다. 하지만 만약 여러분이 조금 더 많은 시간을 할애할 수 있고, 조금 더 많은 컴퓨팅을 할 수 있다면, 그리고 1%의 추가 성능을 짜내고 싶다면, 그것은 여러분이 사용할 수 있는 트릭입니다. 결과적으로 우리는 K-최근접 이웃이 기계학습 알고리즘의 좋은 특성을 많이 가지고 있다는 것을 보았지만, 실제로는 그리 대단하지 않고, 이미지에 그다지 많이 쓰이지는 않는다는 것을 알게 되었습니다.
Linear Classification
다음으로 이야기하고 싶은 것은 선형 분류(linear classification)입니다. 선형 분류는, 다시 말해, 꽤 간단한 학습 알고리즘이지만, 이것은 매우 중요해질 것이고 우리가 전체 신경망(neural networks)과 전체 CNN(convolutional networks)을 만다는 것을 도울 것입니다.
그래서 사람들이 신경망(neural networks)을 가지고 일할 때 흔히 말하는 한 가지 비유를 하자면, 우리는 신경망을 레고 블록과 같은 존재로 생각한다는 겁니다. 신경망의 다른 요소들을 가질 수 있고, 이 요소들을 서로 붙여서 서로 다른 큰 신경망(convolutional networks)들의 탑을 만들 수 있다는 겁니다.

다양한 종류의 딥러닝 응용에서 볼 수 있는 가장 기본적인 구성 요소 중 하나는 이 선형 분류기(linear classifier)입니다. 제 생각에는 실제로 선형 분류에 대해 잘 이해하는 것이 매우 중요하다고 생각하는데. 왜냐하면 이것들은 결국 전체 신경망(neurla networks)에 꽤 잘 일반화될(generalizing) 것이기 때문입니다.

신경망(neural networks)의 이런 모듈적 특성의 또 다른 예는 우리의 연구실에서 이미지 캡션에 관한 몇몇 연구에서 나온 것입니다. 여기서 우리는 이미지를 입력하고 이미지를 설명하는 서술적인 문장을 출력하고자 하는데. 이런 종류의 작용은 우리가 이미지를 보는 하나의 CNN(convolutional neural networks)과 언어에 대해 아는 반복적인 신경망(recurrent neural networks)을 가지고 있다는 겁니다.
그리고 우리는 이 두 조각을 마치 레고 블록처럼 서로 붙여서 전체를 함께 훈련시킬 수 있고 결국엔 심상치 않은 아주 멋진 시스템을 갖추게 될 것입니다. 우리는 수업시간에 이 모델의 세부사항을 살펴보겠지만, 이것은 여러분에게 이 DNN(deep neural networks)은 마치 레고 같은 것이고 이 선형 분류기는 마치 이 거대한 네트워크의 가장 기본적인 구성 요소와 같다는 느낌을 줄 겁니다.
하지만 그건 두 번째 강좌에서 하기에는 너무 과해서, 당분간은 CIFA-10으로 돌아가야 합니다. 자, CIFAR-10에 이런 50,000개의 훈련 예가 있다는 것을 기억하시고, 각각의 이미지는 32 x 32 픽셀 그리고 3개의 컬러 채널이 있습니다. 선형 분류(Linear classification)에서는 K-최근접 이웃과는 조금 다른 접근법을 취하게 될 겁니다.

그래서 선형 분류기(linear classifier)는 우리가 파라메트릭 모델(parametric model)이라고 부르는 것의 가장 간단한 예 중 하나입니다. 이제, 우리의 파라메트릭 모델(parametric model)은 두 가지 다른 요소를 가지고 있는데. 왼쪽에 있는 고양이 이미지를 반영하여, 그리고 이것은 우리가 보통 우리의 입력 데이터를 위해 X로 쓰는 것이며, 또한 보통 W라고 부르는 변수이며 가중치 집합도 문헌에 따라 세타 라고도 합니다.
이제 우리는 데이터 X, 매개변수 W를 모두 포함하는 함수를 쓰려고 하는데, 이것은 10개의 숫자로 CIFA-10의 각 10개 범주에 해당하는 점수를 설명할 겁니다. 고양이에 대한 더 큰 점수처럼 입력 X가 고양이가 될 확률이 더 크다는 해석과 함께[말 잘림]
Question : What is the three?
질문은 “이 세 가지가 무엇이냐?”인데
이 예에서 세 가지는 빨강, 초록, 파랑의 세 가지 색 채널에 해당합니다. 우리는 보통 컬러 이미지를 연구하기 때문에, 그것은 여러분이 버리고 싶지 않을 좋은 정보입니다. 그래서 K-최근접 이웃 세팅에는 매개변수가 없는 대신 우리는 전체 학습 데이터, 전체 학습 세트, 그리고 테스트 타임에 사용하는데, 그러나 이제 파라메트릭 접근방식으로 우리는 훈련 데이터에 대한 지식을 요약하고 그 모든 지식을 이 파라미터, W에 집어넣고 테스트 시간에는 더 이상 실제 학습 데이터가 필요하지 않기에, 버릴 수 있습니다.
우리는 테스트 시간에 오직 이 파라미터, W만 필요로 합니다. 그래서 이제 우리의 모델들이 더 효율적이고 어쩌면 전화기와 같은 작은 장치들에서 작동될 수 있게 해 주는데. 그래서, 딥러닝에 관한 모든 이야기가 이 함수 F에 적합한 구조를 만들어내고 있는 것입니다. 여러분은 다양한 복잡한 방법으로 가중치와 데이터를 결합하는 방법을 위해 다양한 함수 형태(functional form)를 적는 것을 생각해볼 수 있으며, 이것들은 다양한 네트워크 구조(network architectures)에 부합할 수 있습니다. 그러나 이 두 가지를 결합하는 가장 간단한 예는 아마도, 곱하기 위해서일 겁니다. 그리고 이것은 선형 분류기이기 때문에, 여기 우리의 X의 F, W는 단지 W * X와 같은데. 아마도 여러분이 상상할 수 있는 가장 간단한 방정식일 것입니다.
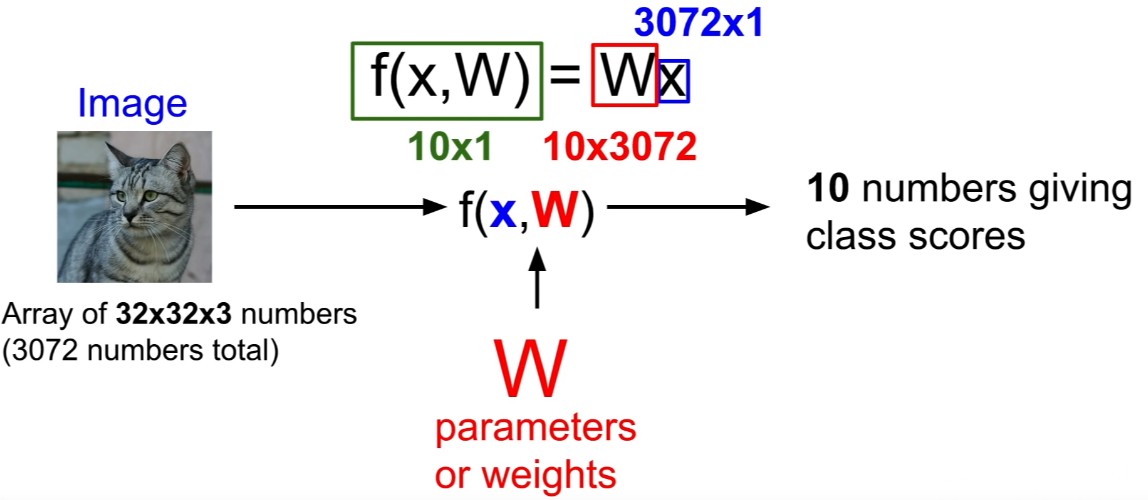
자, 만약 여러분이 이것들의 치수를 풀었다면, 우리의 이미지는 아마도 32 x 32 x 3 값이었을 것이고, 그 다음 우리는 그 값들을 한 항목씩 3,072개의 긴 벡터 열로 확장시킬 겁니다. 그리고 이제 우리는 10개의 클래스 점수로 끝나기를 원하는데. 우리는 이 이미지에 대한 10개의 숫자로 끝맺기를 원하고, 우리에게 10개의 범주 각각에 대한 점수를 주는데. 즉, 이제 우리의 매트릭스인 W는 10 * 3,072이 되어야 합니다. 그래서 이 두 가지를 곱하면 우리는 10 개의 클래스 점수를 주는 하나의 벡터 열로 끝나게 될 것입니다.
또한, 전형적으로, 우리는 종종 학습 데이터와 상호 작용하지 않는 10가지 엘리멘트의 변함없는(constant) 벡터 편향 조건(bias term)을 추가하고, 대신 다른 클래스에 비해 어떤 종류의 데이터 독립적 선호도를 제공합니다. 따라서 데이터 집합이 불균형하고 개보다 고양이가 더 많다면, 예를 들어 고양이에 해당하는 편향 요소(bias elements)가 다른 데이터 집합보다 높을 것이라고 생각할 수 있습니다.
Example with an image with 4 pixels, and 3 classes(cat/dog/ship)

그림처럼 이 함수가 무엇을 하고 있는지를 생각해보면, 이 그림에서 우리는 2 by 2의 간단한 이미지를 왼쪽에서 볼 수 있으며, 총 4개의 픽셀을 가지고 있는데. 선형 분류기(linear classifier)가 작동하는 방식은 이 2 by 2 이미지를 가져다가 네 개의 요소를 가진 기둥 벡터로 늘리는 것이다. 지금 이 예에서는 PPT 슬라이드에 10개를 다 넣을 수 없어서 고양이, 개, 배 등 세 개의 클래스로 제한하는데. 아무튼 이제 가중치 매트릭스(weight matrix)는 4 by 3가 될 것이기 때문에 4개의 픽셀과 세 개의 클래스가 있습니다.
다시 말하지만, 우리는 3가지 요소 편향 벡터(bias vector)를 가지고 있는데, 이 벡터는 우리에게 각 범주에 대한 데이터 독립적 편향 조건(bias term)을 제공합니다. 이제 우리는 고양이의 점수가 이 편향 조건과 함께 추가된 무게 행렬(weight matrix)의 픽셀과 이 행 사이의 입력 결과물(product)이 될 것임을 알 수 있습니다.
그래서, 이런 식으로 본다면, 이 매트릭스의 각 행이 이미지의 일부 템플릿과 일치하는 경우에 선형 분류(linear classification)를 거의 템플릿 매칭 접근법으로(template matching approach) 이해할 수 있을 것입니다.
이제 매트릭스의 행과 이미지의 픽셀을 제공하는 칼럼 사이에 입력 결과 또는 도트 결과가 이 도트 결과를 계산하면 클래스 템플릿과 이미지의 픽셀 사이의 유사성을 얻을 수 있습니다.

그리고 편향은 각 클래스에 대한 데이터 독립성 스케일링 오프셋을 제공한다. 만약 우리가 템플릿 매칭의 이러한 관점에서 선형 분류(linear classification)를 생각한다면, 우리는 실제로 가중치 매트릭스(weight matrix)의 행을 취해서 그것들을 다시 이미지로 풀어서 실제로 그 템플릿들을 이미지로 시각화할 수가 있다.
그리고 이것은 선형 분류기(linear classifier)가 실제로 우리의 데이터를 이해하기 위해 무엇을 하고 있는지 우리에게 알려주는데. 그래서 이 예에서 우리는 이미지에서 선형 분류기(linear classifier)를 훈련시켰습니다. 그리고 이제 아래에서는 CIFAR-10의 10개 카테고리에 해당하는 학습된 가중치 매트릭스(weight matrix)의 행이 무엇인지 시각화하고 있습니다.
이런 식으로 우리는 이 사진들에서 무슨 일이 일어나고 있는지 감지하게 되는 겁니다. 예를 들어, 좌측 하단에 있는 평면 클래스의 템플릿을 보면, 파란색 얼룩과 같은 것으로 이루어져 있는데, 가운데에 있는 얼룩 같은 것과 배경에는 아마도 파란색인데, 이 선형 분류기는 아마도 파랗고 얼룩진 것을 찾고 있을 것처럼 보입니다. 그리고 이러한 특징들은 분류기가 비행기를 더 좋아하게끔 하기 위해서 계속될 겁니다.
이 차 예제를 보면, 가운데를 통해 빨간 얼룩 같은 것이 있고, 윗부분에는 파란 얼룩같은 것이 있는데, 아마도 앞유리가 흐릿한 것 같습니다. 하지만 이건 좀 이상한데, 이건 정말 자동차처럼 보이지 않는 다는 겁니다... ... 실제로 이렇게 생긴 차는 없습니다. 따라서 문제는 선형 분류기가 각 클래스마다 하나의 템플릿만 배우고 있다는 겁니다.
그래서 만약 그 클래스가 어떻게 나타날지에 대한 다양성이 있다면, 그것은 모든 다른 변형, 모든 다른 외관을 평균화하고, 단지 하나의 템플릿만을 사용하여 각각의 범주를 인식하려고 한다는 것입니다.
우리는 또한 말 분류기(horse classifier)에서 이것을 꽤 분명히 볼 수가 있습니다. 말 분류기에서 말들은 보통 잔디 위에 있기 때문에 우리는 바닥의 녹색 물질을 봅니다. 그리고 자세히 살펴보면, 말은 아마도 두 개의 머리를 가지고 있고, 양쪽에 머리를 하나씩 가지고 있는 것처럼 보입니다.
그리나 우리는 머리가 두 개인 말은 본 적이 없습니다. 그러나 선형 분류기는 단지 카테고리당 하나의 템플릿만 배울 수 있기 때문에 할 수 있는 최선을 다하고 있을 뿐입니다. 그리고 우리가 신경망(neural networks)과 더 복잡한 모델로 나아가면서, 우리는 훨씬 더 나은 정확성을 얻을 수 있을 것입니다. 왜냐하면 더 이상 범주당 하나의 템플릿을 배우는 것에 대한 제한을 받지 않기 때문입니다.

선형 분류기의 또 다른 관점은 이 영상들을 점과 높은 차원 공간으로 되돌아가는 것입니다. 그리고 여러분은 우리의 각각의 이미지가 높은 차원 공간에서는 한 점과 같은 것이라고 상상할 수 있을 겁니다. 그리고 이제 선형 분류자는 한 범주와 나머지 범주 사이의 선형 분리를 시도하기 위해 이러한 선형 결정 경계(linear decision boundaries)를 삽입하고 있습니다.
왼쪽 상단에서 우리는 비행기의 훈련 예를 볼 수 있는데, 훈련하는 과정 내내 이 파란색 선을 그어 비행기 클래스를 다른 모든 클래스들과 구분하려고 노력하고 있는 겁니다. 그리고 만약 여러분이 학습 과정 중에 이 선들이 무작위로 시작해서 제대로 데이터를 분리하려고 하는 것을 본다면 사실 꽤 재미있을 겁니다.

그러나 이런 식으로 선형 분류를 생각해 보면, 이 높은 차원적 관점에서 보면, 선형 분류를 만들어 낼 수 있는 몇 가지 문제점들이 무엇인지 다시 보기 시작할 수 있을 겁니다. 그리고 선형 분류기가 완전히 실패할 수 있는 데이터셋의 예를 구축하는 것은 그리 어렵지가 않습니다.
여기 왼쪽에 있는 한 예는, 우리가 두 범주의 데이터 집합을 가지고 있다고 가정해 보면. 그리고 이것들은 모두 다소 인위적인 것일 수도 있지만, 아마도 우리의 데이터 집합은 파란색과 빨간색의 두 가지 범주를 가지고 있을 것입니다. 그리고 파란색 카테고리는 영상의 픽셀 수인데 0보다 큰 픽셀 수는 홀수이며 그리고 0보다 큰 픽셀의 숫자가 짝수인 어떤 것이라도 우리는 빨간 범주로 분류하고 싶다는 겁니다.
만약 여러분이 실제로 비행기의 다른 결정 지역(decisions regions)들이 어떻게 생겼는지 그린다면, 여러분은 우리의 odd number 파란 클래스가 비행기에서 이 두 개의 4분면이 될 것이고, 심지어 그 반대인 2분 면도될 것이라는 것을 알 수 있을 겁니다. 그래서 지금은 하나의 선형선을 그려서 파란색을 빨간색과 구분할 수 있는 방법이 없는 겁니다. 그래서 이것은 선형 분류자가 실제로 힘겹게 몸부림치는(struggle) 예가 될 것입니다.
그리고 이것은 어쩌면 그렇게 인위적인 것이 아닐지도 모릅니다. 픽셀을 세는 대신에, 우리는 실제로 한 이미지의 동물이나 사람의 수가 홀수인 혹은 짝수인지를 세어 보려고 하는 것 일지도 모릅니다. 그래서 이런 종류의 짝수에서 홀수들을 분리하는 평등한 문제는 선형 분류(linear classification)가 전통적인 것과 실제로 투쟁하고 있는 것입니다.
선형 분류기가 실제로 고군분투하는 다른 상황들은 다중모드 상황(multimodal situations)입니다. 우측에, 아마도 우리의 파란색 카테고리는 파란색 카테고리가 사는 세 개의 다른 섬들을 가지고 있는 것이며 그리고 모든 카테고리는 서로 다른 카테고리일 것입니다. 앞서 살펴본 예에서 본 말과 같은 것이 실제로 이런 일이 일어날 수 있는 겁니다. 이 픽셀 공간에서 왼쪽을 보는 말들의 섬과 오른쪽을 보는 말들의 섬이 하나 있을 겁니다.
그리고 이제 이 두 개의 고립된 데이터 섬들 사이에 하나의 선형 경계(linear boundary)를 긋는 좋은 방법은 없습니다. 따라서 공간의 다른 영역에 나타날 수 있는 한 클래스처럼 다중 모달 데이터(multimodal data)가 있는 곳이라면 선형 분류기가 고전할 수 있는 또 다른 장소입니다. 따라서 선형 분류기에는 많은 문제가 있지만, 이것은 매우 단순한 알고리즘이고, 매우 좋고, 해석하기 쉽고, 이해하기 쉬운 알고리즘입니다. 그래서 여러분은 실제로 첫 번째 숙제를 할 때 이런 것들을 시행하게 될 것입니다.

이 시점에서, 우리는 선형 분류기에 해당하는 함수 형태가 무엇인지에 대해 이야기했고. 그리고 우리는 매트릭스 벡터 증식 함수 형태(functional form of matrix vector multiply correspons)는 데이터에 있는 각 카테고리에 대한 하나의 템플릿 매칭과 학습에 대한 이 아이디어에 부합한다는 것을 알아냈으며. 그리고 이 학습된 매트릭스를 갖게 되면, 이 매트릭스를 사용하여 새로운 학습 예제에서 점수를 얻을 수 있다는 것입니다. 그러나 아직 설명하지 않은 것은 데이터 세트에 적합한 W를 선택하는 방법을 실제로 어떻게 선택할 것인가인데. 우리는 좀 전에 함수 형태가 무엇인지, 그리고 이것의 진행상황에 대해 이야기했습니다.

따라서 다음 수업에는 정말 집중해야 할 것인데. 다음 강의에서는 올바른 W를 선택하기 위한 전략과 알고리즘이 무엇인지에 대해 이야기할 것이며. 그리고 이것은 우리에게 손실 함수(loss functions)와 최적화(optimization) 그리고 결국 ConvNets에 대한 질문으로 이어질 것입니다. 여기까지가 다음 주의 프리뷰이며 오늘 우리가 다룬 모든 내용입니다.
'IT 관련 공부' 카테고리의 다른 글
| Python으로 Telegram 챗봇 만들기(4) - 네이버 실시간 인기검색어 받아오기 (0) | 2019.08.22 |
|---|---|
| Python으로 Telegram 챗봇 만들기(3) - 네이버 영화순위 받아오기 (0) | 2019.08.22 |
| Python으로 Telegram 챗봇 만들기(2) - 네이버 날씨 받아오기 (0) | 2019.08.22 |
| Python으로 Telegram 챗봇 만들기(1) - 봇 생성과 멜론차트 받아오기 (3) | 2019.08.22 |
| CS231n Lec1(번역) (0) | 2019.04.11 |
- Total
- Today
- Yesterday
- image classification
- 청도맥주박물관
- 챗본만들기
- 청도맥주
- Python
- 85도씨커피
- Machine Learning
- CS231n
- 칭다오
- chatbot
- 진취덕
- stable diffusion
- ai그림
- 대만여행
- Qingdao
- 텔레그램 챗봇
- 스펀
- AI그림 그리기
- 텔레그램
- 금사탄
- 삼성생명현장실습
- 청도맥주축제
- 챗봇
- 청도여행
- 파이썬
- 예스진지
- telegram
- web ui
- 샹산
- 텔레그램 봇
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |